
路由和中间件
本文主要用于介绍GoBlog项目中两个最为重要的部分——路由和中间件。这两个部分可以说是本项目的重要组成部分,下面我们会逐个进行学习和分析,并大概介绍其在项目中的作用。
路由
goblog 需要一款灵活的路由器来搭配 MVC 程序结构,恰巧Go Web 开发有各式各样的路由器可供选择。这个时候可能就有朋友要问了,什么是路由啊,路由有什么用呢?额……其实我在学的时候也有这样的问题,那就慢慢往下看吧。
什么是路由?
路由,就是URL地址到业务处理代码的映射。当用户输入一个URL地址时,服务器改知道要返回什么内容,一个 URL 到一个具体的处理函数之间的映射叫做一条路由。

多条路由组成路由表,路由表主要用于路由查找,根据不同的路由表的组织形式,可以有不同的查找方法。

给定一个URL,找到对应的处理函数的过程叫做路由查找。路由器就是用来管理路由表并进行路由查找的。

所以,在Web系统中一个路由系统由路由、路由表和路由匹配三部分功能组成。
路由实现由三种方法,分别是基于映射表、正则表达式以及tries结构的路由实现,下面将会一一介绍。
基于映射表的路由实现
Go内建标准包bet/http中路由的实现是基于映射表实现的,也是最简单的路由。
http怎么处理请求
Go 语言中处理 HTTP 请求主要跟两个东西相关:ServeMux 和 Handler。
ServeMux 本质上是一个 HTTP 请求路由器(或者叫多路复用器,Multiplexor)。它把收到的请求与一组预先定义的 URL 路径列表做对比,然后在匹配到路径的时候调用关联的处理器(Handler)。
下面来看 HandleFunc函数的定义:
1 | func HandleFunc(pattern string, handler func(ResponseWriter, *Request)) { |
参数:
pattern是 URI 的规则,例如/或者abouthandler是供调用的函数
http.HandleFunc() 函数是对 DefaultServeMux.HandleFunc() 的封装,当 http.ListenAndServe(addr string, handler Handler) 的第二个参数为 nil 时,会使用DefaultServeMux.HandleFunc()
net/http包中路由的实现
在net/http包中实现路由的机构提是ServeMux,其结构定义如下:
1 | type ServeMux struct { |
结构体字段很简单,我们重点看m变量,是一个map类型,即key-value结构,就是我们所说的路由表。key就是路由的路径,value是一个muxEntry对象,muxEntry结构如下:
1 | type muxEntry struct { |
pattern是对应的路径,h就是对应的处理函数。当我们进行路由注册时候,实质上就是将路径和HomeHandler对象构建成一个muxEntry对象,然后加入到ServeMux的m中。
接下来我们再看路由的查找,既然路由表是有map实现的,那么路由的查找过程自然就是通过路径从map中查找对应的muxEntry,然后获取对应的handler即可。
以上就是net/http包中自己路由的实现。非常简单,同时也意味着功能有限。
http.ServeMux 的局限性
http.ServeMux 在 goblog 中使用,会遇到以下几个问题:
- 不支持 URI 路径参数
- 不支持请求方法过滤
- 无法直接从路由上区分 POST 或者 GET 等 HTTP 请求方法,只能手动判断。
- 不支持路由命名
- 路由命名是一套允许我们快速修改页面里显示 URL 的机制。
优点
- 标准库意味着随着 Go 打包安装,无需另行安装
- 测试充分
- 稳定、兼容性强
- 简单,高效
缺点
- 缺少 Web 开发常见的特性
- 在复杂的项目中使用,需要你写更多的代码
基于正则表达式的路由实现
该包是基于正则表达式实现的路由。该路由支持分组、restful风格路径的定义、绑定路由请求的方法(GET、POST等)、限定路径使用http还是https协议等功能。在本项目中所使用到的路由就是这个。
实现原理分析
通过mux.NewRouter()方法返回了一个Router结构体对象。该结构体对象也实现了ServeHTTP方法,在该方法中实现了对路由的匹配和转发。所以覆盖作为http.ListenAndServe的第二个参数,替代了默认的路由分发对象DefaultServeMux。
在该包中Router的ServeHTTP方法对路由的匹配和分发部分,本质上是和默认的路由分发器DefaultServeMux的实现是一样的。不同的是路由的管理以及匹配上。
Router 结构体如下:
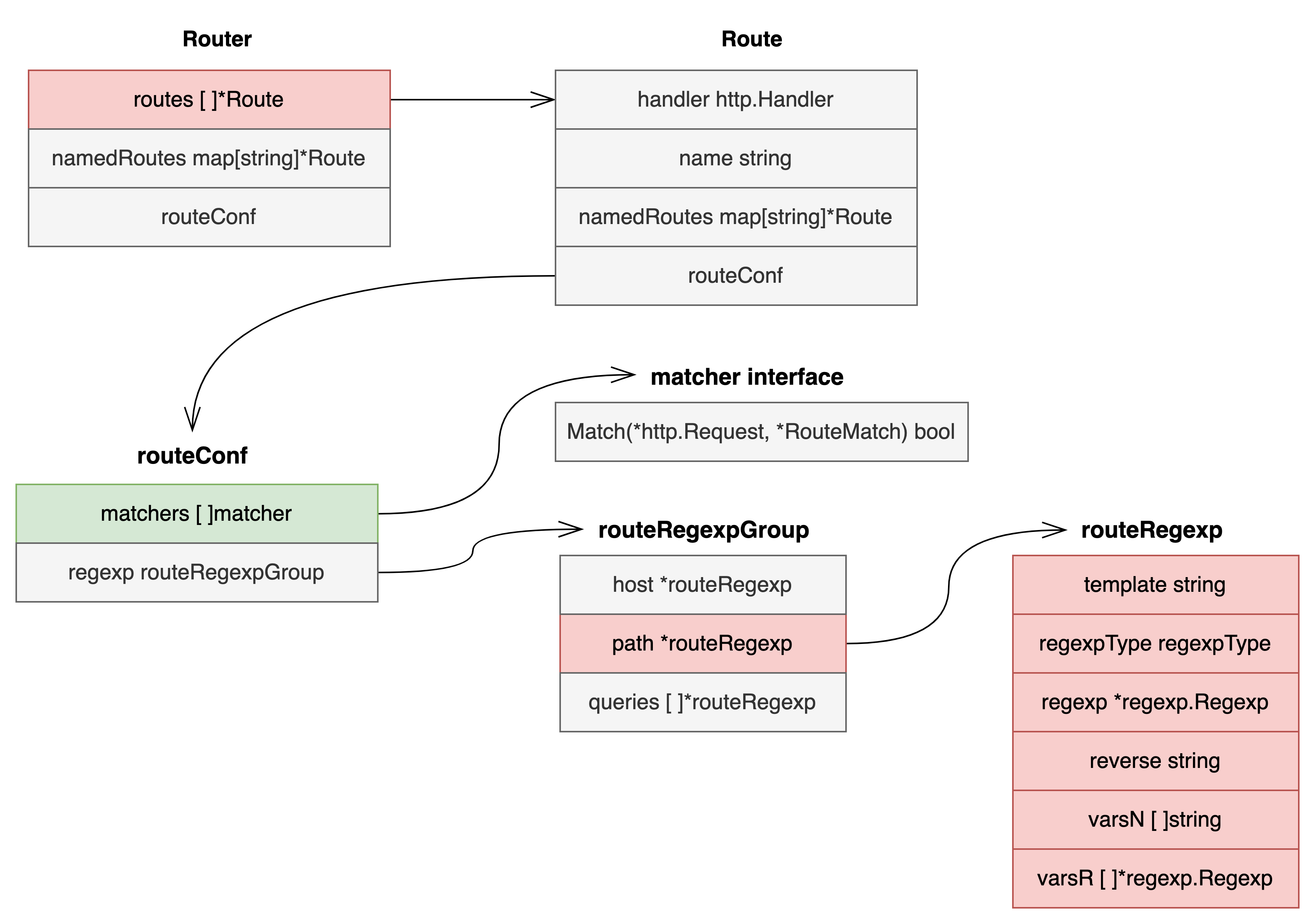
这里我们只列出来核心的字段,省略了一些辅助字段。这里有几个主要的字段:
- Router中的routes:Route切片类型,角色是路由表,存储所有的路由。
- Route:一个具体的路由,handler字段存储的是具体的处理函数,同时每个路由的路径是在最后的routeRegexp结构体中的。
- matchers字段:切片类型,存储了该路由下的所有要匹配的规则。matchers的类型是一个matcher接口,定义了Match方法。其中routeRegexp结构体实现了该方法,所以一个routeRegexp实例就是一个matcher。
- routeRegexp结构体:该结构体代表了路由中具体的路径的匹配规则。将路由中的路径转换成对应的正则表达式,存储与regexp字段中。
routeRegexp结构体中的主要字段分别如下:
- template:保存的是路由的路径模版。比如
r.HandleFunc("/product/{id:[0-9]+}", ProductHandler)中,则是"/product/{id:[0-9]+}" - regexpType:正则类型,目前支持regexpTypePath、regexpTypeHost、regexpTypePrefix、regexpTypeQuery四种类型。比如
r.HandleFunc("/product/{id:[0-9]+}", ProductHandler)就是路径匹配regexpTypePath。而r.Host("www.example.com")就是域名匹配regexpTypeHost。稍后我们会一一介绍。 - regexp:是根据路由中的模版路径构造出来的正则表达式。以
"/product/{id:[0-9]+}"为例,最终构造的正则表达式是^/product/(?P<v0>[0-9]+)$�
reverse: - varsN:是路径模式中花括号{}中的变量个数。以
"/product/{id:[0-9]+}"为例,varsN则等于[]{“id”}。 - varsR:是路径模式中每个花括号{}对应的正则表达式。以
"/product/{id:[0-9]+}"为例,varsR则等于[]{"^[0-9]+$"}。如果路由中是设置r.HandleFunc("/product/{id}", ProductHandler),varsR的元素则是[]{"^[^/]+�"}的正则表达式。
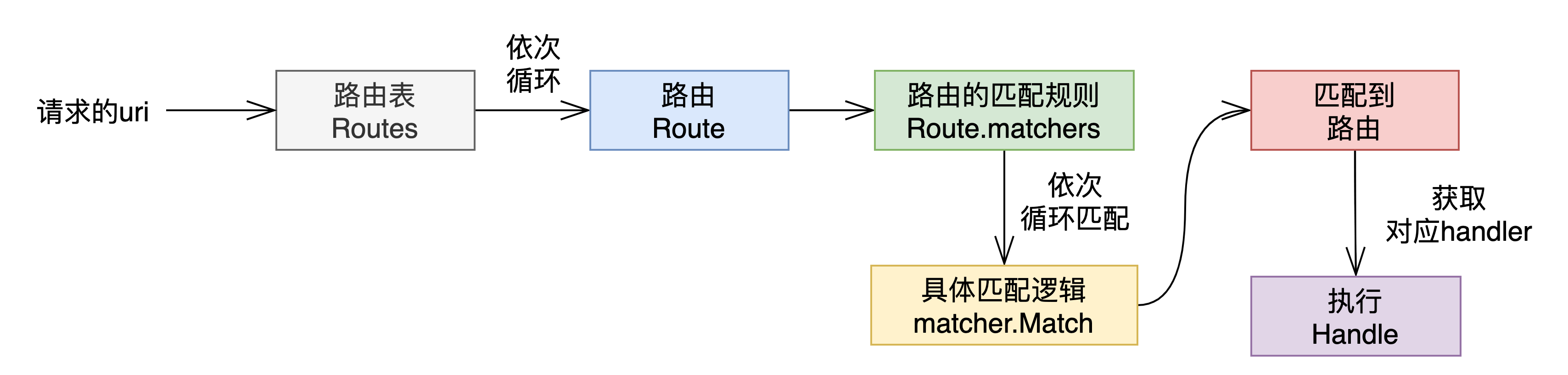
根据路由表及路由的结构,具体的路由匹配查找基本过程如下:第一步,从 Router.routes 开始依次循环第二步,从每个路由中的 matchers 中循环,看请求的路径是否符合 matchers 中的每一项规则,如果都匹配,则说明找到了该路由,否则继续步骤 1。
支持的功能
- 匹配特定的域名或子域名
- 给路径增加前缀
- 限制路由的请求方法(GET、POST等)
- 支持路由分组
- 支持中间件
路由解析
gorilla/mux 的路由解析采用的是 精准匹配 规则,而 net/http 包使用的是 长度优先匹配 规则。
- 精准匹配 指路由只会匹配准确指定的规则,这个比较好理解,也是较常见的匹配方式。
- 长度优先匹配 一般用在静态路由上(不支持动态元素如正则和 URL 路径参数),优先匹配字符数较多的规则。
一般 长度优先匹配 规则用在静态内容处理上比较合适,动态内容,例如我们的 goblog 这种动态网站,使用 精准匹配 会比较方便。
基于 tries 结构的路由实现
gin 框架中的路由
大名鼎鼎的 gin 框架采用的就是前缀树结构实现的路由。我们先来看一下 gin 框架中路由是如何定义的:
1 | package main |
很简单,首先通过 gin.New()初始化一个 gin 对象 g,然后通过 g.POST 或 g.GET 等方法就可以注册路由。很明显,路由注册过程也限制了请求的方法。
当然,还有一个方法是允许任何请求方法都能访问该路径的,就是 Any:
1 | g.Any("/", HomeHandler) |
Any 方法本质上是定义了一组方法名,然后依次调用对应的方法将该路由进行注册,如下:
1 | var anyMethods = []string{ |
实现原理
相比较 map/hash 字典实现的优点:利用字符串公共前缀来减少查询时间,减少无谓的字符串比较。
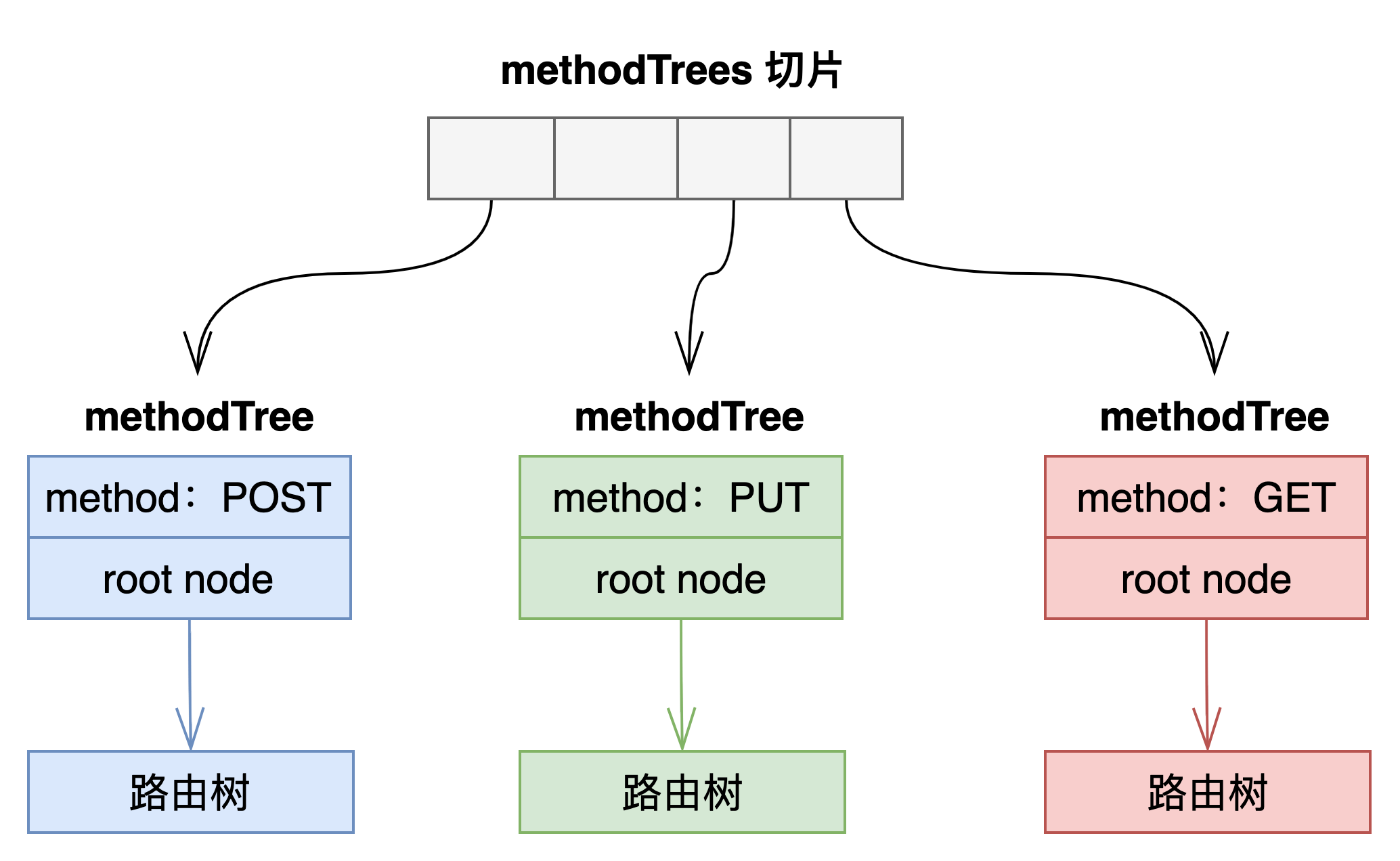
上述示例中的g.POST("/abc/info", InfoHandler)路由,只会注册到 POST 方法的路由树中。若通过 GET 方法请求该路径,则在搜索的时候,在 GET 方法的路由树中就找不到该路由。这样就起到了通过路由限制请求方法的作用。
路由树节点的数据结构
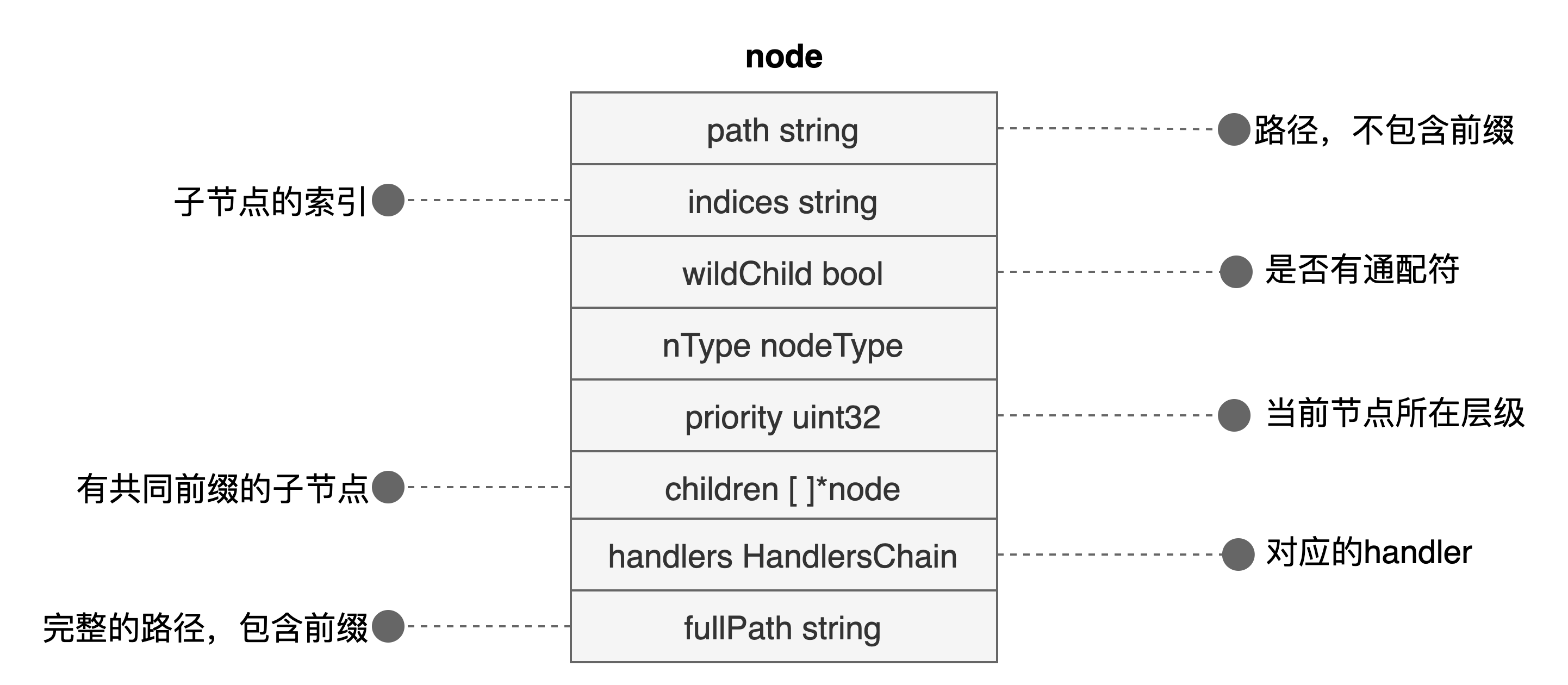
前缀树中的路由都是基于这个 node 数据结构来进行构建的。其中包含了一个路由中的基本元素:路径 fullPath、对应的处理函数 handlers。其中 handlers 包含了中间件处理函数,因此这里使用一个 handlersChain 表示。
另外一个关键字段是 children,具有相同路径前缀的子节点通过 children 节点来构成父、子关系。
路由树的构建
第一个路由的注册:
1 | g.POST("/abc/info", InfoHandler) |
因为是第一个路由注册,路由树是空的。所以直接构建一个 node 节点,然后将该 node 节点作为 POST 方法路由树的根节点插入即可。如下图:

接着注册第二个路由:
1 | g.POST("/abc/info/detail", DetailHandler) |
这个路由的特点是和路由”/abc/info”有共同的前缀,所以会将该路由作为第一个路由的子节点放到 children 中。如下图:

这里主要有三个变化:
- 一个是根节点的 priority 由 1 变成了 2;
- 一个是 children 中多了一个子节点路由;
- 最后一个是 indices 字段的值变成了”/“,这个是第一个子节点的 path 字段的第一个字符,用于匹配时索引使用。
在子节点中,要注意的是 path 的值,因为前缀是”/abc/info”了,所以这里 path 是”/detail”。但 fullPath 依然是注册时完整的路径。
接下来,再注册第三个路由:
1 | g.POST("/abc/list", ListHandler) |
这个路由的特点是和前两个路由有共同的前缀”/abc/“,所以首先会将现在的根节点进行拆分,拆分成”/abc/“ 和”info”。而 info 和原来的”/abc/info/detail” 又有共同的前缀 info,所以原来的”/abc/info/detail”就变成了 info 的子节点。而”/abc/list”除去前缀”/abc/“后,剩余”list”子节点,作为”/abc/“的子节点。如下:
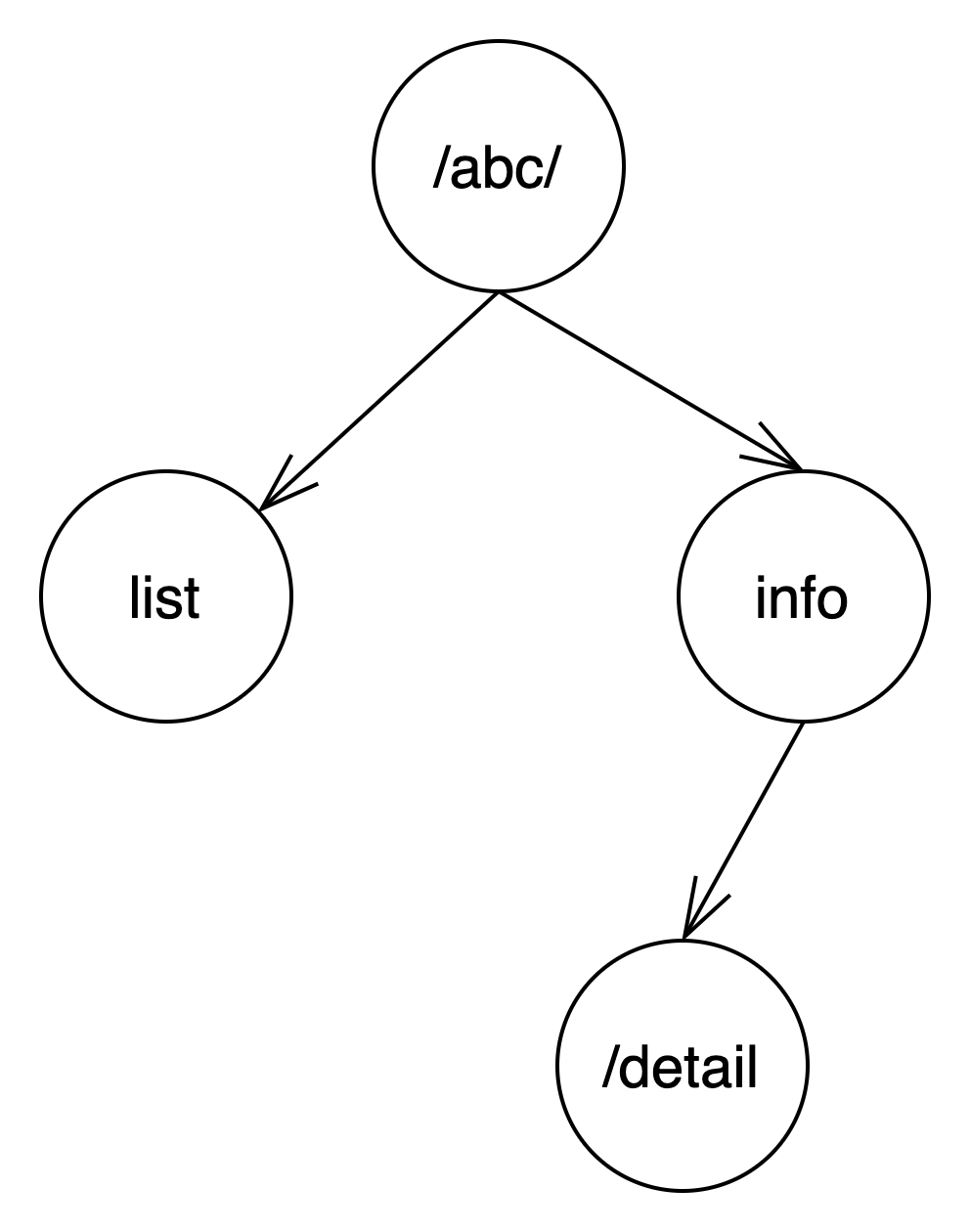
那么,按节点组成的路由树就如下所示:
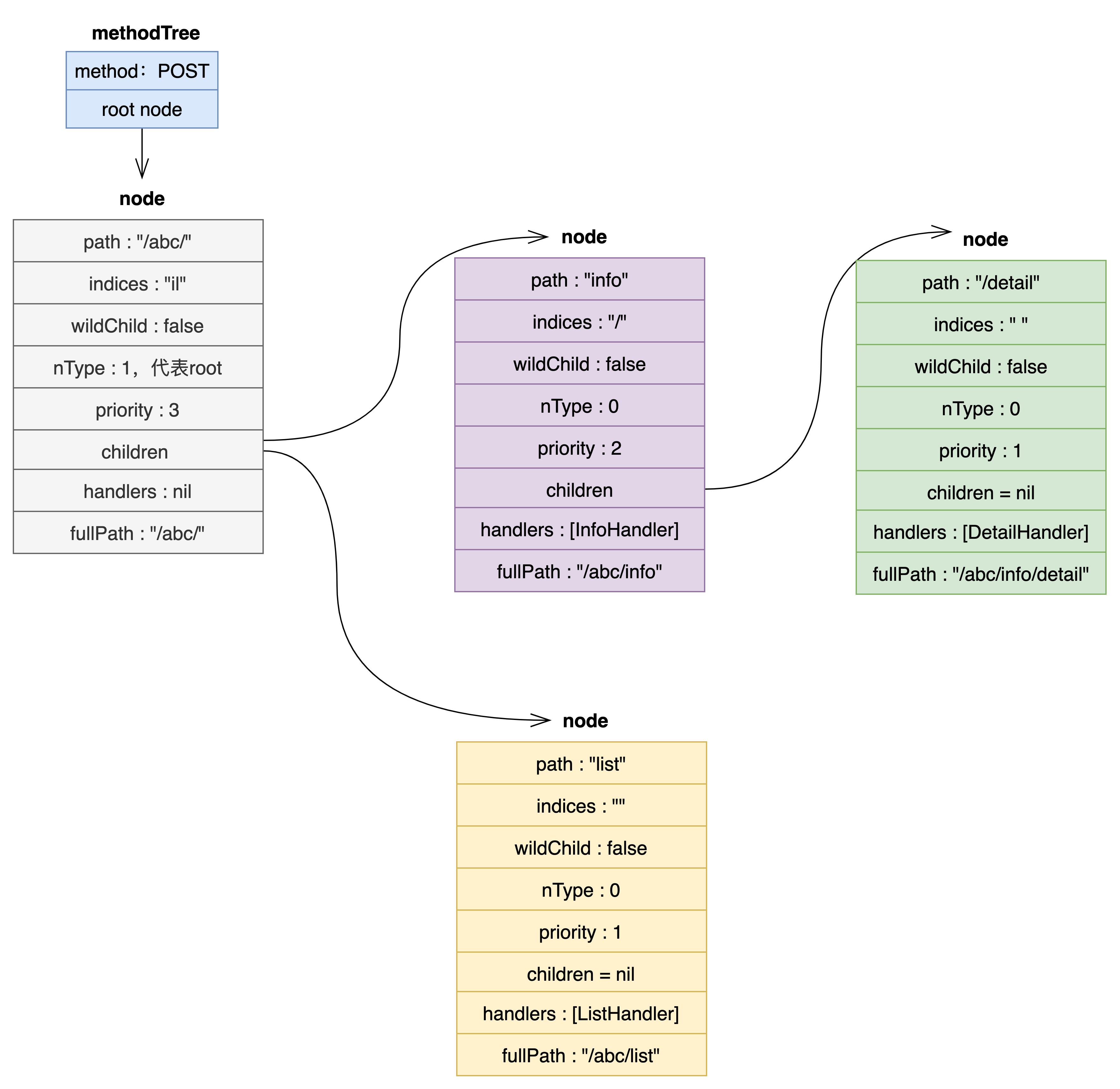
这里,首先看根节点的变化:
- handlers 变为 nil。因为该节点不是一个具体的路径,只是一个前缀,所以具体的 handler 下移到了子节点 info 节点。
- path 变为了前缀”/abc/“。
- indices 字段值变为了”il”,其中 i 是第一个子节点中 path 字段的第一个字符,l 是第二个子节点中 path 字段的第一个字符。
- priority 字段变成 3:代表从自身开始及子节点共有 4 个。
- children 字段变成了两个直接子节点。
- fullPath 字段变为了”/abc/“。
其次,是从原根节点中拆分出一个 info 节点。最后是 detail 节点成为 info 节点的子节点。
中间件
中间件是一种计算机软件,可为操作系统提供的软件应用程序提供服务,以便于各个软件之间的沟通,特别是系统软件和应用软件。广泛用于web应用和面向服务的体系结构等。
纵观GO语言,中间件应用比较普遍,主要应用:
- 记录对服务器发送的请求(request)
- 处理服务器响应(response )
- 请求和处理之间做一个权限认证工作
- 远程调用
- 安全
- 等等
中间件处理程序是简单的http.Handler,它包装另一个http.Handler做请求的一些预处理和/或后处理。它被称为“中间件”,因为它位于Go Web服务器和实际处理程序之间的中间位置。
在gin框架下实现中间件
1 | r := gin.Default() 创建带有默认中间件的路由,默认是包含logger和recovery中间件的 |
总结
至此,我们就大致了解了路由和中间件。在本项目中,路由和中间件实现了大多数功能,因此深刻地理解这两个概念能够帮助我更好的理解代码。