
聊天室
这次真成全栈工程师了。第三个 Go 语言项目,简单地实现了一个基于 TCP 连接的聊天室。

实现功能也比较简单,用户输入昵称进入聊天室,进入聊天室后会向其他用户广播,用户可以看到聊天室的所有聊天记录和当前在线人数,支持@其他人,支持敏感词检测。
由于本项目也是基于书籍中的教程进行的开发,所以在此还是大概记录一下完成该项目学到的东西。
WebSocket
本项目最重要的组成之一,本项目便是基于 WebSocket 进行开发的。
WebSocket 是一种在单个 TCP 连接上进行全双工通信的协议,用于在 Web 应用程序中创建实时、双向的通信通道。
传统的 HTTP 请求通常是一次请求、一次相应,而 WebSocket 则可以建立一个持久连接,允许服务器即时向客户端推送数据,同时也可以接受客户端发送的数据。 WebSocket 相比于传统的轮询或长轮询方式,能够显著减少网络流量和延迟,提高数据传输的效率和速度。它对实时 Web 应用程序和在线游戏的开发非常有用。
WebSocket 可以在浏览器和服务器之间建立一条双向通信的通道,实现服务器主动向浏览器推送消息,而无需浏览器向服务器不断发送请求。其原理是在浏览器和服务器之间建立一个 “套接字”,通过 “握手” 的方式进行数据传输。由于该协议需要浏览器和服务器都支持,因此需要在应用程序中对其进行判断和处理。
原理
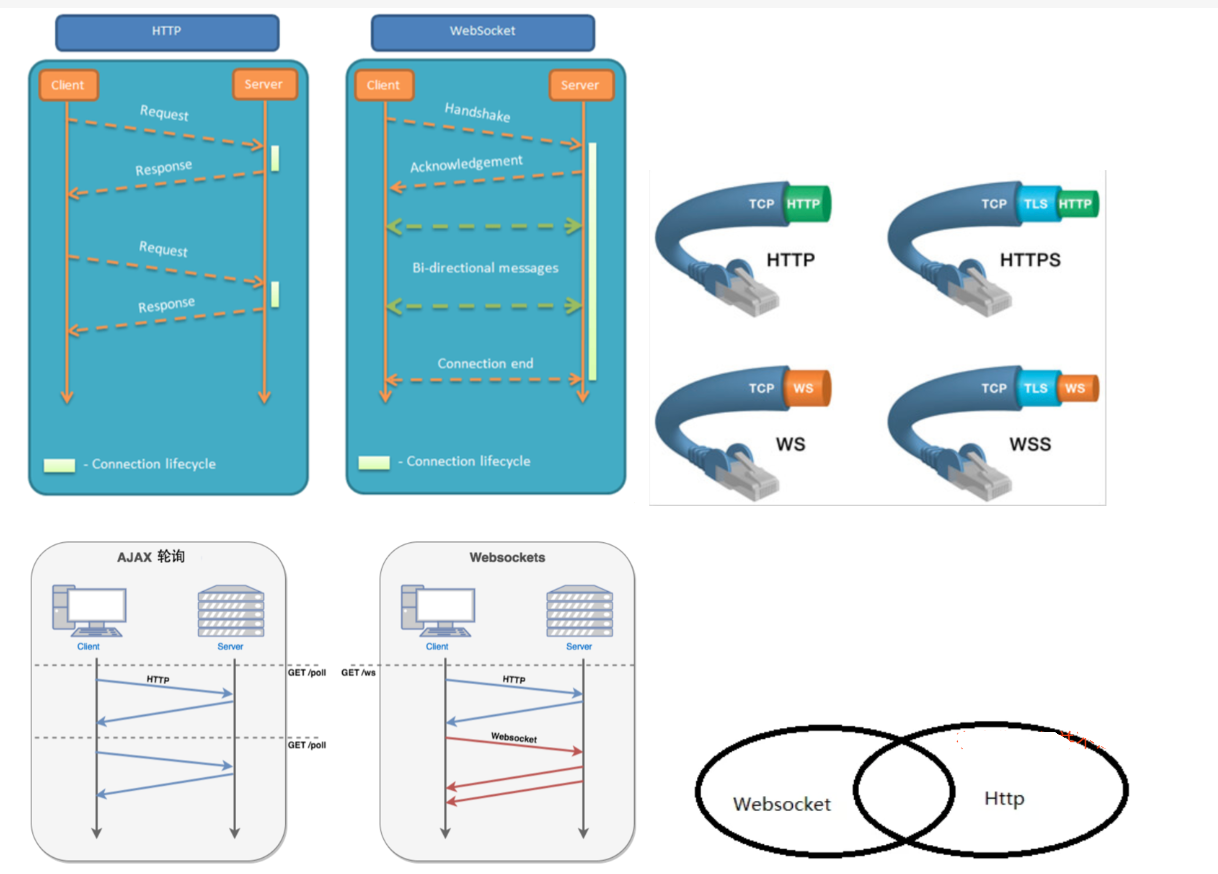
WebSocket 是 HTML5 开始推出的基于 TCP 协议的双向通信协议,其优势在于与 HTTP 协议兼容、开销小、通信高效。WebSocket 让客户端和服务器之间建立连接,并通过这个持久连接实时地进行双向数据传输。
其实 WebSocket 最主要的特点就是建立了一个可持久化的 TCP 连接,这个连接会一直保留,直到客户端或者服务器发起中断请求为止。WebSocket 通过 HTTP/1.1 协议中的 Upgrade 头信息来告诉服务器,希望协议从 HTTP/1.1 升级到 WebSocket 协议。
WebSocket 建立在 HTTP 协议之上,所有的 WebSocket 请求都会通过普通的 HTTP 协议发送出去,然后在服务器端根据 HTTP 协议识别特定的头信息 Upgrade,服务端也会判断请求信息中 Upgrade 是否存在。 这里面 HTTP 是必不可少的,不然 WebSocket 根本无法建立。特别的,WebSocket 在握手时采用了 Sec-WebSocket-Key 加密处理,并采用 SHA-1 签名。
一旦建立了 WebSocket 连接,客户端和服务器端就可以互相发送二进制流或 Unicode 字符串。所有的数据都是经过 mask 处理过的,mask 的值是由服务器端随机生成的。在数据进行发送之前,必须先进行 mask 处理,这样可以有效防止数据被第三方恶意篡改。
最后需要说明一下的是,WebSocket 的通信协议是基于帧(数据包)的。在数据发送时,一个完整的数据包可以分为多个帧进行发送,而每一个帧都包含了数据的一部分,同时还包含了帧头信息。
区别
WebSocket 和 HTTP
HTTP 是一个无状态的协议,使客户端向服务器请求资源,并从服务器接受响应。客户端使用 HTTP 请求/响应语法,即请求发送到服务器之后,服务器向客户端返回 HTML 文件、图像和其他媒体内容。
WebSocket 通信协议尝试在较大范围内改进 Web 实时通信和插件技术,并提供全双工、基于事件的通信而无需采用低效的轮询方式。开发人员可以从 Web 浏览器的 JS 端轻松地创建 WebSocket 连接并发送数据,进而实现应用程序的实时数据传输的实现。
由于 WebSocket 是面向消息的,因此它更加适用于实时通信,而 HTTP 更适用于请求和服务器-客户端通信的响应。
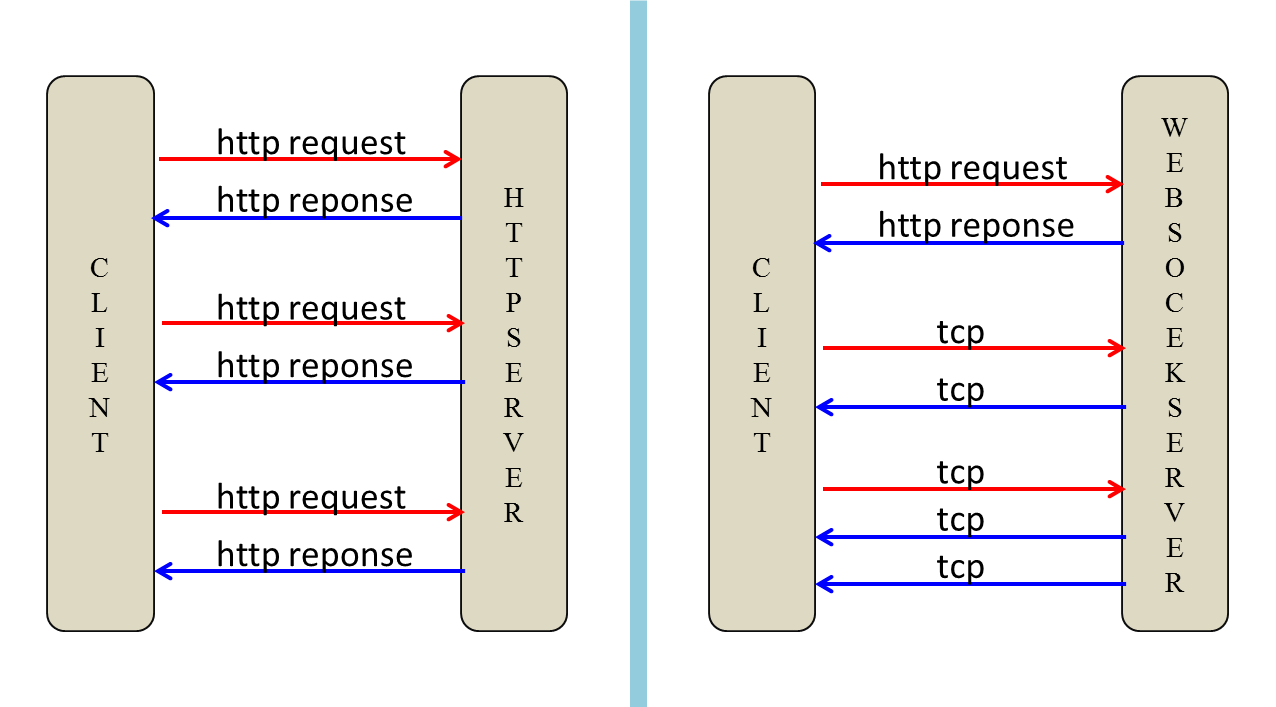
区别总结
- 连接方式不同: HTTP 是一种单向请求-响应协议,每次请求需要重新建立连接,而 WebSocket 是一种双向通信协议,使用长连接实现数据实时推送。
- 数据传输方式不同: HTTP 协议中的数据传输是文本格式的,而 WebSocket 可以传输文本和二进制数据。
- 通信类型不同: HTTP 主要用于客户端和服务器之间的请求和响应,如浏览器请求网页和服务器返回网页的 HTML 文件。WebSocket 可以实现双向通信,常常用于实时通信场景。
- 性能方面不同: 由于 HTTP 的每次请求都需要建立连接和断开连接,而 WebSocket 可以在一次连接上进行多次通信,WebSocket 在性能上比 HTTP 有优势。
WebSocket 和 TCP
WebSocket 和 HTTP 都是基于 TCP 协议的应用层协议。
- 层次结构: WebSocket 是应用层协议,而 TCP 是传输层协议。
- 协议特点: TCP 是一种面向连接的协议,使用三次握手建立连接,提供可靠的数据传输。而 WebSocket 是一种无状态的协议,使用 HTTP 协议建立连接,可以进行双向通信,WebSocket 的数据传输比 TCP 更加轻量级。
- 数据格式: TCP 传输的数据需要自定义数据格式,而 WebSocket 可以支持多种数据格式,如 JSON、XML、二进制等。WebSocket 数据格式化可以更好的支持 Web 应用开发。
连接方式: TCP 连接的是物理地址和端口号,而 WebSocket 连接的是 URL 地址和端口号。
WebSocket 和 Socket
协议不同
Socket 是基于传输层 TCP 协议的,而 Websocket 是基于 HTTP 协议的。Socket 通信是通过 Socket 套接字来实现的,而 Websocket 通信是通过 HTTP 的握手过程实现的。
持久化连接
传统的 Socket 通信是基于短连接的,通信完成后即断开连接。而 Websocket 将 HTTP 协议升级后,实现了长连接,即建立连接后可以持续通信,避免了客户端与服务端频繁连接和断开连接的过程。
双向通信
传统的 Socket 通信只支持单向通信,即客户端向服务端发送请求,服务端进行响应。而 Websocket 可以实现双向通信,即客户端和服务端都可以发起消息,实时通信效果更佳。
效率
Socket 通信具有高效性和实时性,因为传输数据时没有 HTTP 协议的头信息,而 Websocket 除了HTTP协议头之外,还需要发送额外的数据,因此通信效率相对较低。
应用场景
Socket 适用于实时传输数据,例如在线游戏、聊天室等需要快速交换数据的场景。而 Websocket 适用于需要长时间保持连接的场景,例如在线音视频、远程控制等。
基础代码框架
在基本了解 WebSocket 之后,尝试去使用 TCP 和 WebSocket 分别来写一个简单的聊天室。具体代码就不在这里赘述了,可以去下面的参考文献中找一下。
OK,在基本学习了如何使用 WebSocket 来完成一个聊天室的设计之后,我们来正式开启项目的设计。基础框架和流程如下:
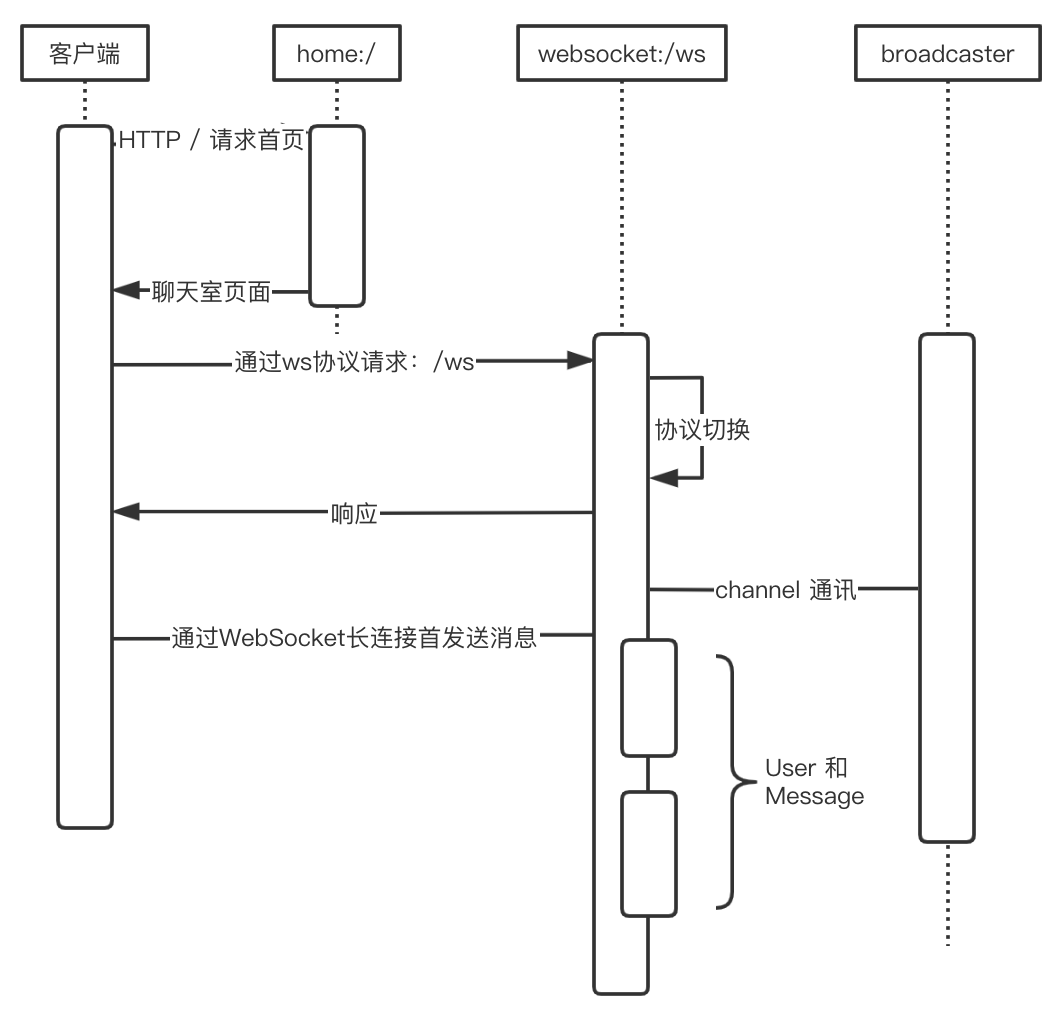
目录结构
1 | ├── README.md |
相关目录说明如下:
- cmd:该目录几乎是 Go 圈约定俗成的,Go 官方以及开源界推荐的方式,用于存放 main.main;
- logic:用于存放项目核心业务逻辑代码,和 service 目录是类似的作用;
- server:存放 server 相关代码,虽然这是 WebSocket 项目,但也可以看成是 Web 项目,因此可以理解成存放类似 controller 的代码;
- template:存放静态模板文件;
四个类型
User:
1 | type User struct { |
broadcaster:
1 | // broadcaster 广播器 |
Message:
1 | // 给用户发送的消息 |
offlineProcessor:
1 | type offlineProcessor struct { |
核心流程
本项目的核心流程分为两个部分,一个是前端的设计,另一个是后端的 API 开发。有关前端的部分我想可能还得一段时间才会去学习,所以这一部分就只写后端的内容。
新用户来了
由于在第二个项目中已经把注册登录功能实现的很好了,所以在本聊天室中并未设置注册登录功能,为了方便识别用户,我们简单地要求用户输入昵称。
昵称在建立 WebSocket 连接时,通过 HTTP 协议传递,因此可以通过 http.Request 获取到。虽然没有注册功能,但依然要解决昵称重复的问题。这里必须引出 Broadcaster 了。
1 | type broadcaster struct { |
因为 Broadcaster.Broadcast() 在一个单独的 goroutine 中运行,按照 Go 语言的原则,应该通过通信来共享内存。因此,我们定义了 5 个 channel,用于和其他 goroutine 进行通信。
- enteringChannel:用户进入聊天室时,通过该 channel 告知 Broadcaster,即将该用户加入 Broadcaster 的 users 中;
- leavingChannel:用户离开聊天室时,通过该 channel 告知 Broadcaster,即将该用户从 Broadcaster 的 users 中删除,同时需要关闭该用户对应的 messageChannel,避免 goroutine 泄露,后文会讲到;
- messageChannel:用户发送的消息,通过该 channel 告知 Broadcaster,之后 Broadcaster 将它发送给 users 中的用户;
- checkUserChannel:用来接收用户昵称,方便 Broadcaster 所在 goroutine 能够无锁判断昵称是否存在;
- checkUserCanInChannel:用来回传该用户昵称是否已经存在;
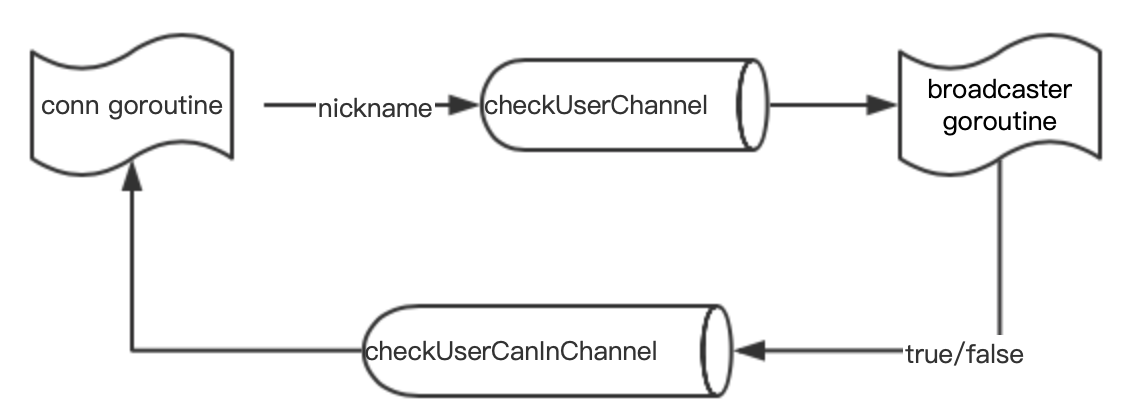
两个 goroutine 通过两个 channel 进行通讯,因为 conn goroutine(代表用户连接 goroutine)可能很多,通过这种方式,避免了使用锁。
如果用户已存在,连接会断开;否则创建该用户的实例(新建 User 类型):
1 | user := logic.NewUser(conn, nickname, req.RemoteAddr) |
至此,用户算是进入了聊天室,新用户进入,一方面给 TA 发送欢迎的消息,另一方面需要通知聊天室的其他人,有新用户进来了(新建 Message 类型)。
接下来看看发送消息的过程,发送消息分两情况,它们的处理方式有些差异:
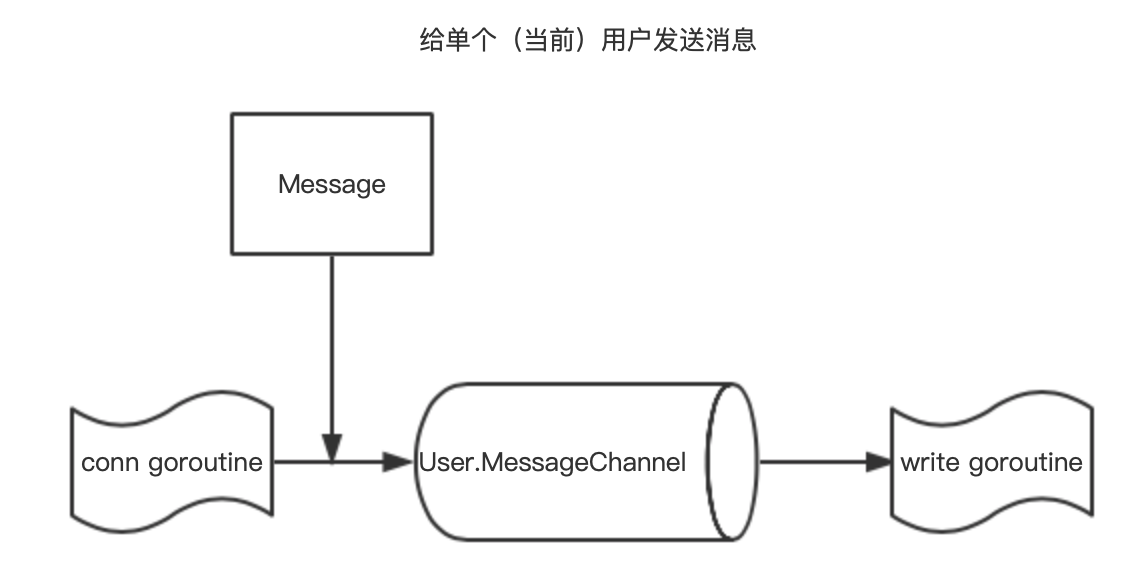
- 给单个用户(当前)用户发送消息
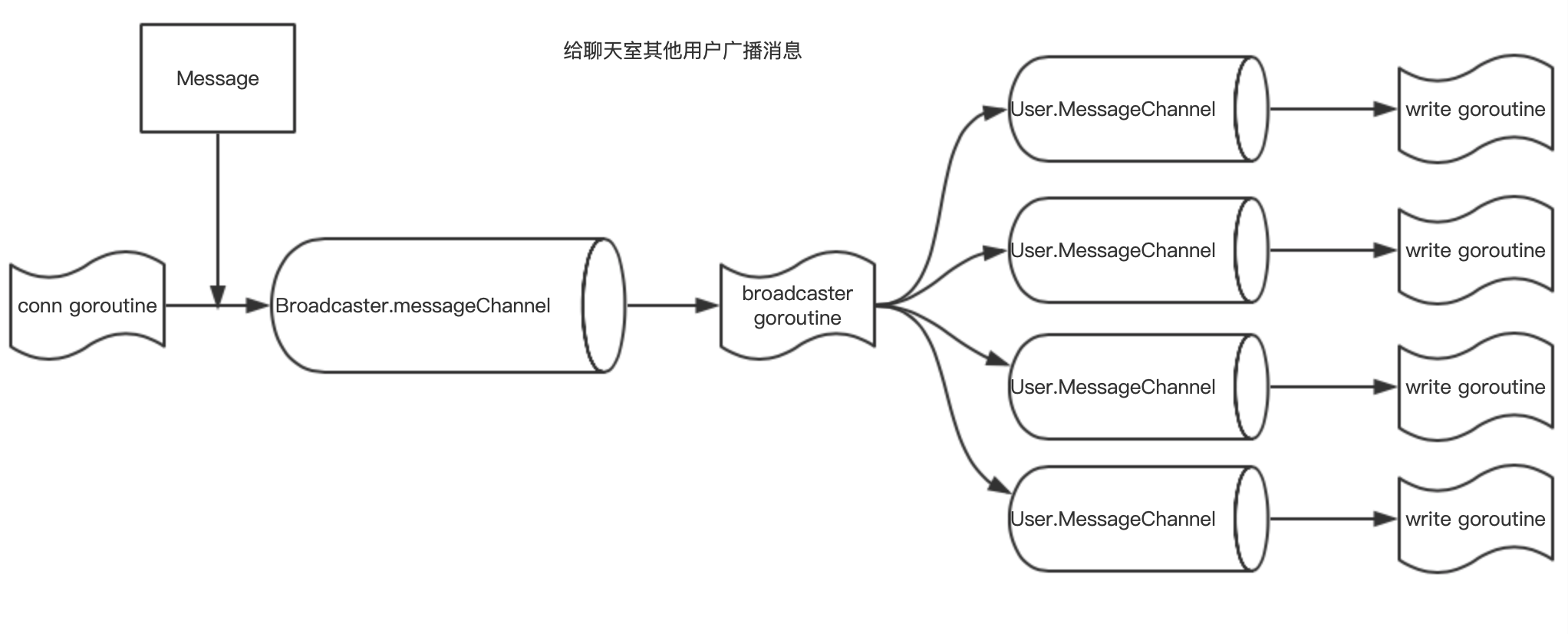
- 给聊天室其他用户广播消息
给当前用户发送消息的情况比较简单:conn goroutine 通过用户实例(User)的字段 MessageChannel 将 Message 发送给 write goroutine。
给聊天室其他用户广播消息自然需要通过 broadcaster goroutine 来实现:conn goroutine 通过 Broadcaster 的 MessageChannel 将 Message 发送出去,broadcaster goroutine 遍历自己维护的聊天室用户列表,通过 User 实例的 MessageChannel 将消息发送给 write goroutine。
用户走了
1 | // 6. 用户离开 |
这里主要做了三件事情:
- 在 Broadcaster 中注销该用户;
- 给聊天室中其他还在线的用户发送通知,告知该用户已离开;
- 根据 err 处理不同的 Close 行为。关于 Close 的 Status 可以参考 rfc6455 的 第 7.4 节;
单例模式
Go 不是完全面向对象的语言,只支持部分面向对象的特性。面向对象中的单例模式是一个常见、简单的模式。
简介
该模式规定一个类只允许有一个实例,而且自行实例化并向整个系统提供这个实例。因此单例模式的要点有:
- 只有一个实例;
- 必须自行创建;
- 必须自行向整个系统提供这个实例。
单例模式主要避免一个全局使用的类频繁地创建与销毁。当你想控制实例的数量,或有时候不允许存在多实例时,单例模式就派上用场了。
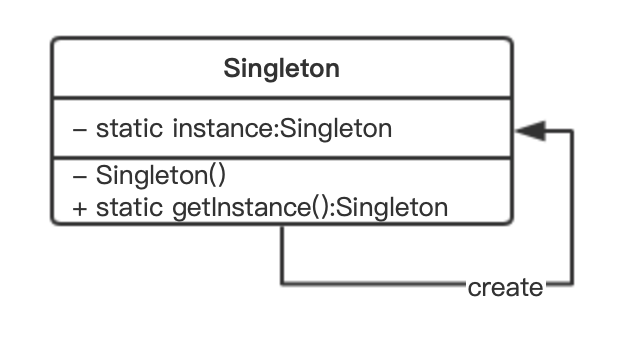
通过该类图我们可以看出,实现一个单例模式有如下要求:
- 私有、静态的类实例变量;
- 构造函数私有化;
- 静态工厂方法,返回此类的唯一实例;
根据实例化的时机,单例模式一般分成饿汉式和懒汉式。
- 饿汉式:在定义 instance 时直接实例化,private static Singleton instance = new Singleton();
- 懒汉式:在 getInstance 方法中进行实例化;
那两者有什么区别或优缺点?
- 饿汉式单例类在自己被加载时就将自己实例化。即便加载器是静态的,饿汉式单例类被加载时仍会将自己实例化。单从资源利用率角度讲,这个比懒汉式单例类稍差些。从速度和反应时间角度讲,则比懒汉式单例类稍好些。
- 然而,懒汉式单例类在实例化时,必须处理好在多个线程同时首次引用此类时的访问限制问题,特别是当单例类作为资源控制器在实例化时必须涉及资源初始化,而资源初始化很有可能耗费时间。这意味着出现多线程同时首次引用此类的几率变得较大。
1 | // 饿汉式单例模式 |
1 | // 懒汉式单例模式 |
作用
单例模式是一种创建型设计模式, 让你能够保证一个类只有一个实例, 并提供一个访问该实例的全局节点。
单例模式同时解决了两个问题, 所以违反了单一职责原则:
保证一个类只有一个实例。 为什么会有人想要控制一个类所拥有的实例数量? 最常见的原因是控制某些共享资源 (例如数据库或文件) 的访问权限。
它的运作方式是这样的: 如果你创建了一个对象, 同时过一会儿后你决定再创建一个新对象, 此时你会获得之前已创建的对象, 而不是一个新对象。
注意, 普通构造函数无法实现上述行为, 因为构造函数的设计决定了它必须总是返回一个新对象。
为该实例提供一个全局访问节点。 还记得你 (好吧, 其实是我自己) 用过的那些存储重要对象的全局变量吗? 它们在使用上十分方便, 但同时也非常不安全, 因为任何代码都有可能覆盖掉那些变量的内容, 从而引发程序崩溃。
和全局变量一样, 单例模式也允许在程序的任何地方访问特定对象。 但是它可以保护该实例不被其他代码覆盖。
还有一点: 你不会希望解决同一个问题的代码分散在程序各处的。 因此更好的方式是将其放在同一个类中, 特别是当其他代码已经依赖这个类时更应该如此。
goroutine 泄露
在 Go 中,goroutine 的创建成本低廉且调度效率高。Go 运行时能很好的支持具有成千上万个 goroutine 的程序运行,数十万个也并不意外。但是,goroutine 在内存占用方面却需要谨慎,内存资源是有限的,因此你不能创建无限的 goroutine。
每当你在程序中使用 go 关键字启动 goroutine 时,你必须知道该 goroutine 将在何时何地退出。如果你不知道答案,那可能会内存泄漏。
原因
造成goroutine泄露的几个原因:
- 从 channel 里读,但是同时没有写入操作
- 向 无缓冲 channel 里写,但是同时没有读操作
- 向已满的 有缓冲 channel 里写,但是同时没有读操作
- select操作在所有case上都阻塞()
- goroutine进入死循环,一直结束不了
可见,很多都是因为channel使用不当造成阻塞,从而导致goroutine也一直阻塞无法退出导致的。
实际场景
生产者消费者场景
1 | func main() { |
生产协程进入死循环,不断产生数据。消费协程,也就是主协程只消费期中的 3 个值,然后主协程就再也不消费 channel 中的数据,去做其他事情了。此时生产协程放了一个数据到 channel 中,但已经不会有协程消费该数据,所以生产协程阻塞。此时,若没有人再消费 channel 中的数据,生产协程是被泄露的协程
解决方法:
总的来说,要解决channel引起的goroutine leak问题,主要是看在channel阻塞goroutine时,该goroutine的阻塞是正常的,还是可能导致协程永远没有机会执行。若可能导致协程永远没有机会执行,则可能会导致协程泄露。 所以,在创建协程时就要考虑到它该如何终止。
解决一般问题的办法就是,当主线程结束时,告知生产线程,生产线程得到通知后,进行清理工作:或退出,或做一些清理环境的工作。
1 | func main() { |
上面的代码中,协程通过一个channel来得到结束的通知,这样它就可以清理现场。防止协程泄露。 通知协程结束的方式,可以是发送一个空的struct,更加简单的方式是直接close channel。如上图所示。
master work 场景
在该场景下,我们一般是把工作划分成多个子工作,把每个子工作交给每个goroutine来完成。此时若处理不当,也是有可能发生goroutine泄漏的。我们来看一下实际的例子:
1 | // function to add an array of numbers. |
以上代码在主协程中,把一个数组分成两个部分,分别交给两个worker协程来计算其值,这两个协程通过channel把结果传回给主协程。 但,在以上代码中,我们只接收了一个channel的数据,导致另一个协程在写channel时阻塞,再也没有执行的机会。 要是我们把这段代码放入一个常驻服务中,看的更加明显:
http server 场景
1 | // 把数组s中的数字加起来 |
如果运行以上程序,并在浏览器中输入:
1 | http://127.0.0.1:8001/sum |
并不断刷新浏览器,来不断发送请求,可以看到以下输出:
1 | 2 |
这个输出是我们的http server的协程数量,可以看到:每请求一次,协程数就增加一个,而且不会减少。说明已经发生了协程泄露(goroutine leak)。
解决方法:
解决的办法就是不管在任何情况下,都必须要有协程能够读写channel,让协程不会阻塞。
time.After
1 | func ProcessMessage(ctx context.Context, in <-chan string) { |
在标准库 time.After 的文档中有一段说明:
等待持续时间过去,然后在返回的 channel 上发送当前时间。它等效于 NewTimer().C。在计时器触发之前,计时器不会被垃圾收集器回收。
所以,如果还没有到 5 分钟,该函数返回了,计时器就不会被 GC 回收,因此出现了内存泄露。因此大家使用 time.After 时一定要仔细,一般建议不用它,而是使用 time.NewTimer:
1 | func ProcessMessage(ctx context.Context, in <-chan string) { |
敏感词处理
任何由用户产生内容的公开软件,都必须做好敏感词的处理。作为一个聊天室,当然要处理敏感词。
其实敏感词(包括广告)检测一直以来都是让人头疼的话题,很多大厂,比如微信、微博、头条等,每天产生大量内容,它们在处理敏感词这块,会投入很多资源。所以,这不是一个简单的问题,本书不可能深入探讨,但尽可能多涉及一些相关内容。
一般来说,目前敏感词处理有如下方法:
- 简单替换或正则替换
- DFA(Deterministic Finite Automaton,确定性有穷自动机算法)
- 基于朴素贝叶斯分类算法
简单替换或正则替换
1 | // 1. strings.Replace |
类似于上面的代码(两种代码类似),我们会使用一个敏感词列表(坏蛋、发票、傻子、傻大个、傻人),来对目标字符串进行检测与替换。比较适合于敏感词列表和待检测目标字符串都比较小的场景,否则性能会有较大影响。(正则替换和这个是类似的)
DFA
DFA全称为:Deterministic Finite Automaton,即确定有穷自动机。其特征为:有一个有限状态集合和一些从一个状态通向另一个状态的边,每条边上标记有一个符号,其中一个状态是初态,某些状态是终态。但不同于不确定的有限自动机,DFA中不会有从同一状态出发的两条边标志有相同的符号。
敏感词过滤很适合用DFA算法,用户每次输入都是状态的切换,如果出现敏感词,既是终态,就可以结束判断。
我们把数组形式的敏感词整理为一个树状结构,准确的说是一个森林。
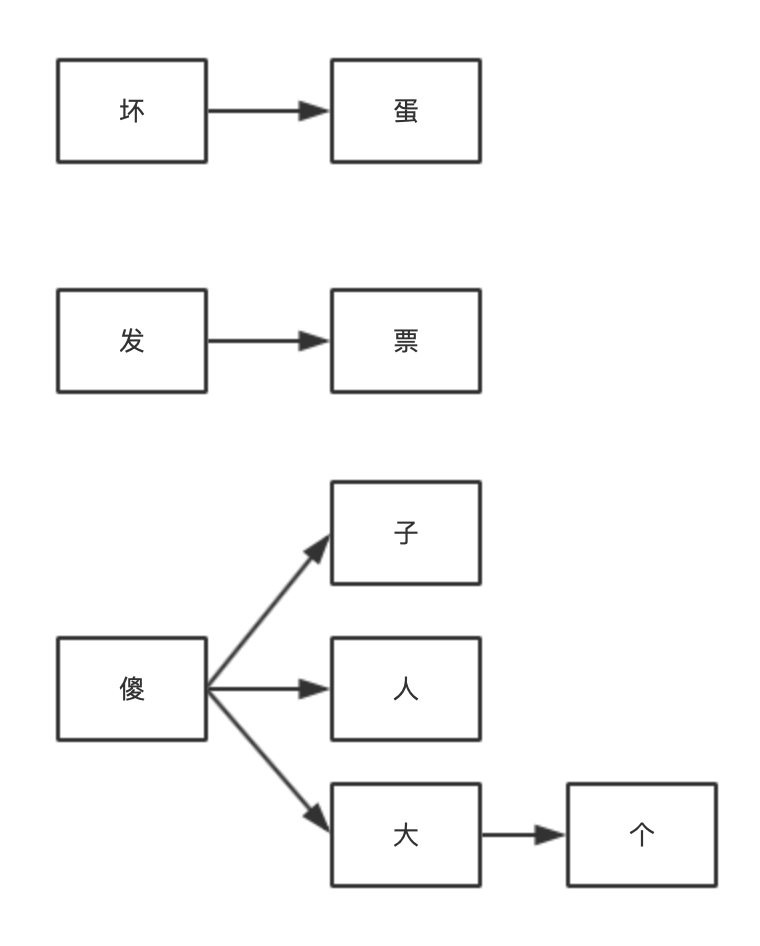
这样查找敏感词就变成了一个查找路径的问题,如果用户输入的内容中包含一个从根节点到叶子节点的完整路径,就说明包含敏感词。
算法实现逻辑是循环用户输入的字符串,依次查找每个字符是否出现在树的节点上,比如用户输入“你是傻大个”,从第一个字开始判断,“你”不在树的根节点上,进入下一步,“是”也不在根节点上,进入下一步,“傻”出现在了根节点上,这时状态切换,下一步的查找范围变为“傻”的子节点;“大”出现在子节点中,状态再次切换为“大”的子节点;“个”出现在子节点中,并且为叶子节点,所以包含敏感词。
基于朴素贝叶斯分类算法
贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。而朴素朴素贝叶斯分类是贝叶斯分类中最简单,也是常见的一种分类方法。这是一种“半学习”形式的方法,它的准确性依赖于先验概率的准确性。
敏感词检测步骤:
- 分词:对获取的评论进行分词处理,采用的是jieba分词
- 去除无意义词:采用的是哈工大的词表,遍历每一条评论,判断是否在无用词表(这里主要包含特殊字符,标点符号,感叹词等)中,从而达到去除无意词的效果
- 通过评论建立自己的词库,采用并集处理,达到词库中词的唯一性
- 建立向量:将去除无意词后的评论装换成稀疏矩阵,采用的是多项式模型,这里考虑到评论一般都比较短小,相对来说,几乎每一个词都会影响到最终的判断,所以采用多项式模型,而没有采用伯努利模型
- 划分训练集和测试集:采用random.shuffle()函数将数据随机排序,然后再通过切片处理划分数据,为了保证每条评论与其对应的标签保持一致,采用zip()函数将评论和标签绑定在一起
- 调用sklearn里面内置的贝叶斯算法接口
总结
到这里本项目也已经基本完成了,就行文章开始写的那样,这并不是一片详细的教程,只是用来记录一下完成这个项目所学到的东西。
总的来说,这个项目的教程写的也不是很详细,很多函数的实现还是要自己去完成,但是核心的内容作者都会很详细地解释,而且重要的内容其实都可以搜到。
现在我知道为什么这个项目是基于 TCP,而不是 UDP 的了。
参考文献
WebSocket:
- https://apifox.com/apiskills/what-is-websocket/
- https://apifox.com/apiskills/websocket-socket-tcp-http/
- https://xie.infoq.cn/article/1b9128d59e2538604e441bc53
单例模式:
goroutine 泄露:
- https://hoverzheng.github.io/post/technology-blog/go/goroutine-leak%E5%92%8C%E8%A7%A3%E5%86%B3%E4%B9%8B%E9%81%93/
- https://segmentfault.com/a/1190000040161853
敏感词检测: