
Redis为何快得飞起?解密闪电侠的内存魔法
Redis 为什么这么快,这是我在了解 Redis 之前最大的疑问,即使你只是刚刚听说 Redis,对 Redis 的查询速度想必也是有所耳闻。
在没有深入学习之前,我只会回答因为 Redis 是依赖于内存实现的,所以速度快的飞起。但是,仅仅依靠内存,是不是就把设计人员费的心思给浪费了呢。
在了解为什么之前,我们先来看一下到底有多快。
官方使用基准测试的结果是,单线程的 Redis 吞吐量可以达到 10W/每秒,如下图所示:

内存存储:速度的基础
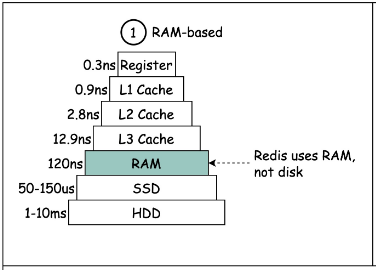
Redis 是一个内存数据库,它的数据存储在内存中,而计算机访问内存比起磁盘读写要快出数个数量级。因此,相较其他需要从磁盘读取数据的传统数据库而言,Redis 的速度要快得多。内存存储使Redis天生就具备了高速基因,这只是它快速的基础。
此外,由于数据直接从内存进行读写,而不必过多考虑如何将它们高效地保存到磁盘上(只有将数据以 RDB 的方式持久化时才会面对这个问题),这也使得 Redis 可以直接使用高效的底层数据结构。
单线程模型:化繁为简的极致
Redis 是单线程,主要是指 Redis 的网络IO和键值对读写是由一个线程来完成的,这也是 Redis 对外提供键值存储服务的主要流程。
多线程必然会面临对于共享资源的访问,这时候通常的做法就是加锁,虽然是多线程,这时候就会变成串行的访问。也就是多线程编程模式会面临的共享资源的并发访问控制问题。
同时多线程也会引入同步原语来保护共享资源的并发访问,代码的可维护性和易读性将会下降。
Redis 的线程模型在不同版本有所不同:
- 2.0 版本:Redis 使用单个线程在事件循环中处理网络请求与执行操作指令,然后其他的后台线程负责释放 RDB/AOF 过程生成的临时文件资源与刷盘;
- 4.0 版本:Redis 添加了一个线程,用于异步执行
UNLINK(异步删除指定键)、FLUSHALL ASYNC(清空所有 DB)和FLUSHDB ASYNC(清空指定 DB)这些比较重的删除指令; - 6.0 版本:Redis 允许通过修改
io-threads和io-threads-do-reads修改 IO 线程数。
另外一提,读写指令要保持单线程,这个设计的理由是因为 CPU 对内存的操作已经足够高效,因此性能瓶颈不大可能来自于 CPU ,而主要来自于内存和网络 IO,因此执行命令的线程有一个足矣。
非阻塞I/O:高并发处理的法宝
首先,Redis 是跑在单线程中的,所有的操作都是按照顺序线性执行的,但是由于读写操作等待用户输入或输出都是阻塞的,所以 I/O 操作在一般情况下往往不能直接返回,这会导致某一文件的 I/O 阻塞导致整个进程无法对其它客户提供服务,而 I/O 多路复用 就是为了解决这个问题而出现的。
Linux 中的IO多路复用机制是指一个线程处理多个IO流。多路是指网络连接,复用指的是同一个线程。简单来说,在 Redis 只运行单线程的情况下,该机制允许内核中,同时存在多个监听套接字和已连接套接字。内核会一直监听这些套接字上的连接请求或数据请求。一旦有请求到达,就会交给 Redis 线程处理,这就实现了一个 Redis 线程处理多个IO流的效果。
文件事件是对连接 socket 操作的一个抽象。当端口监听 socket 准备 accept 新连接,或者连接 socket 准备好读取请求、写入响应、关闭时,就会产生一个文件事件。IO 多路复用程序负责同时监听多个 socket,当这些 socket 产生文件事件时,就会触发事件通知,文件分派器就会感知并获取到这些事件。
虽然多个文件事件可能会并发出现,但 IO 多路复用程序总会将所有产生事件的 socket 放入一个队列中,通过这个队列,有序的把这些文件事件通知给文件分派器。
文件事件分派器接收 I/O 多路复用程序传来的套接字,并根据套接字产生的事件类型,调用相应的事件处理器。
服务器会为执行不同任务的套接字关联不同的事件处理器,这些处理器是一个个的函数,他们定义了这个事件发生时,服务器应该执行的动作。

Redis 封装了 4 种多路复用程序,每种封装实现都提供了相同的 API 实现。编译时,会按照性能和系统平台,选择最佳的 IO 多路复用函数作为底层实现,选择顺序是,首先尝试选择 Solaries 中的 evport,如果没有,就尝试选择 Linux 中的 epoll,否则就选择大多 UNIX 系统都支持的 kqueue,这 3 个多路复用函数都直接使用系统内核内部的结构,可以服务数十万的文件描述符。
如果当前编译环境没有上述函数,就会选择 select 作为底层实现方案。select 方案的性能较差,事件发生时,会扫描全部监听的描述符,事件复杂度是 O(n),并且只能同时服务有限个文件描述符,32 位机默认是 1024 个,64 位机默认是 2048 个,所以一般情况下,并不会选择 select 作为线上运行方案。

单线程处理 I/O 请求的性能瓶颈
1、后台 Redis 通过监听处理事件队列中的消息来通过单线程处理命令,如果一个命令的执行时间很久,就会影响整个 server 的性能;
耗时的操作命令有下面几种:
- 操作 bigkey:bigkey 在写入和删除的时候,需要的时间都会很长;
- 使用复杂度过高的命令;
- 大量 key 集中过期:Redis 的过期机制也是在主线程中执行的,大量 key 集中过期会导致处理一个请求时,耗时都在删除过期 key,耗时变长;
- 淘汰策略:淘汰策略也是在主线程执行的,当内存超过 Redis 内存上限后,每次写入都需要淘汰一些 key,也会造成耗时变长;
- AOF刷盘开启 always 机制:每次写入都需要把这个操作刷到磁盘,写磁盘的速度远比写内存慢,会拖慢 Redis 的性能;
- 主从全量同步生成 RDB:虽然采用 fork 子进程生成数据快照,但 fork 这一瞬间也是会阻塞整个线程的,实例越大,阻塞时间越久;
上面的这几种问题,我们在写业务的时候需要去避免,对于 bigkey,Redis 在4.0推出了 lazy-free 机制,把 bigkey 释放内存的耗时操作放在了异步线程中执行,降低对主线程的影响。
2、并发量非常大时,单线程读写客户端 IO 数据存在性能瓶颈
使用 Redis 时,几乎不存在 CPU 成为瓶颈的情况, Redis 主要受限于内存和网络。随着硬件水平的提升,Redis 中的性能慢慢主要出现在网络 IO 的读写上。虽然采用 I/O 多路复用机制,但是读写客户端数据依旧是同步 IO,只能单线程依次读取客户端的数据,无法利用到CPU多核。
为了提升网络 IO 的读写性能,Redis 在6.0推出了多线程,同过多线程的 IO 来处理网络请求。不过需要注意的是这里的多线程仅仅是针对客户端的读写是并行的,Redis 处理事件队列中的命令,还是单线程处理的。
高效的数据结构:内功深厚
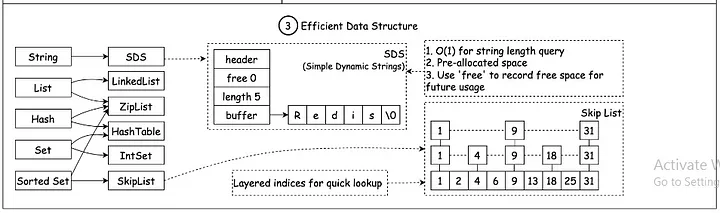
Redis 的高速很大程度上依赖于它丰富而高效的数据结构,而它们在底层实现上,都针对不同的使用场景进行了精心的设计和优化。
在 Redis数据结构五兄弟:数据江湖的武林盟主这篇博客中我们详细地分析了 Redis 中的五种基础数据结构以及其底层数据结构,可以非常清楚地看到,为了尽可能地将 Redis 的查询速度提高到极致,每一个基础数据结构的底层都用了最快的解决方案。具体内容可以去看那篇博客,这里就不细致讨论了。
结语
Redis为什么这么快?除了依赖内存存储,它还采用了单线程模型、非阻塞I/O、高效的数据结构、智能压缩和优化、以及多种高级特性。这些技术手段结合在一起,使得Redis成为了数据库界的速度王者。如果你还没用过Redis,赶紧试试吧,让它来为你的项目提速,体验飞一般的感觉!
关于本文讨论的这个内容,其实是一个在面试时经常会被问到的问题,内容其实并不多,主要是 Redis 设计时的一些特性,需要好好理解。