
Redis的键值过期和内存淘汰机制:内存的游戏
Redis 是一个 k-v 型数据库,我们所有的数据都是存放在内存中的,但是内存是有大小限制的,不可能无限制的增量。
想要把不需要的数据清理掉,一种办法是直接删除,这个咱们前面章节有详细说过;另外一种就是设置过期时间,缓存过期后,由Redis系统自行删除。
这边需要注意的是,缓存过期之后,并不是马上删除的,那Redis是怎么删除过期数据的呢?主要通过两个方式
- 惰性删除
- 通过定时任务,定期选取部分数据删除
但是无论是惰性删除还是定期删除,都可能存在删除不尽的情况,无法删除完全,还有就是 Redis 中的使用过程中,随着写数据的增加,Redis 中的内存不够用了,这时候就需要 Redis 的内存淘汰策略了。
Redis 的「内存淘汰策略」和「过期删除策略」,很容易混淆,这两个机制虽然都是做删除的操作,但是触发的条件和使用的策略都是不同的。
- Redis 过期策略指的是 Redis 使用那种策略,来删除已经过期的键值对;
- Redis 内存淘汰机制指的是,当 Redis 运行内存已经超过 Redis 设置的最大内存之后,将采用什么策略来删除符合条件的键值对,以此来保障 Redis 高效的运行。
下面还是来详细地看看这些内容以及实现原理吧。
过期删除策略
如何设置过期时间?
先说一下对 key 设置过期时间的命令。 设置 key 过期时间的命令一共有 4 个:
expire <key> <n>:设置 key 在 n 秒后过期,比如 expire key 100 表示设置 key 在 100 秒后过期;pexpire <key> <n>:设置 key 在 n 毫秒后过期,比如 pexpire key2 100000 表示设置 key2 在 100000 毫秒(100 秒)后过期。expireat <key> <n>:设置 key 在某个时间戳(精确到秒)之后过期,比如 expireat key3 1655654400 表示 key3 在时间戳 1655654400 后过期(精确到秒);pexpireat <key> <n>:设置 key 在某个时间戳(精确到毫秒)之后过期,比如 pexpireat key4 1655654400000 表示 key4 在时间戳 1655654400000 后过期(精确到毫秒)
当然,在设置字符串时,也可以同时对 key 设置过期时间,共有 3 种命令:
set <key> <value> ex <n>:设置键值对的时候,同时指定过期时间(精确到秒);set <key> <value> px <n>:设置键值对的时候,同时指定过期时间(精确到毫秒);setex <key> <n> <valule>:设置键值对的时候,同时指定过期时间(精确到秒)。
如果你想查看某个 key 剩余的存活时间,可以使用 TTL <key> 命令。
1 | # 设置键值对的时候,同时指定过期时间位 60 秒 |
如果突然反悔,取消 key 的过期时间,则可以使用 PERSIST <key> 命令。
1 | # 取消 key1 的过期时间 |
如何判定 key 是否过期?
每当我们对一个 key 设置了过期时间时,Redis 会把该 key 带上过期时间存储到一个过期字典(expires dict)中,也就是说「过期字典」保存了数据库中所有 key 的过期时间。
过期字典存储在 redisDb 结构中,如下:
1 | typedef struct redisDb { |
过期字典数据结构结构如下:
- 过期字典的 key 是一个指针,指向某个键对象;
- 过期字典的 value 是一个 long long 类型的整数,这个整数保存了 key 的过期时间;
过期字典的数据结构如下图所示:

字典实际上是哈希表,哈希表的最大好处就是让我们可以用 O(1) 的时间复杂度来快速查找。当我们查询一个 key 时,Redis 首先检查该 key 是否存在于过期字典中:
- 如果不在,则正常读取键值;
- 如果存在,则会获取该 key 的过期时间,然后与当前系统时间进行比对,如果比系统时间大,那就没有过期,否则判定该 key 已过期。
过期键判断流程如下图所示:

过期删除策略有哪些?
在说 Redis 过期删除策略之前,先跟大家介绍下,常见的三种过期删除策略:
- 定时删除;
- 惰性删除;
- 定期删除;
接下来,分别分析它们的优缺点。
定时删除策略是怎么样的?
定时删除策略的做法是,在设置 key 的过期时间时,同时创建一个定时事件,当时间到达时,由事件处理器自动执行 key 的删除操作。
定时删除策略的优点:
- 可以保证过期 key 会被尽快删除,也就是内存可以被尽快地释放。因此,定时删除对内存是最友好的。
定时删除策略的缺点:
- 在过期 key 比较多的情况下,删除过期 key 可能会占用相当一部分 CPU 时间,在内存不紧张但 CPU 时间紧张的情况下,将 CPU 时间用于删除和当前任务无关的过期键上,无疑会对服务器的响应时间和吞吐量造成影响。所以,定时删除策略对 CPU 不友好。
惰性删除策略是怎么样的?
惰性删除策略的做法是,不主动删除过期键,每次从数据库访问 key 时,都检测 key 是否过期,如果过期则删除该 key。
惰性删除策略的优点:
- 因为每次访问时,才会检查 key 是否过期,所以此策略只会使用很少的系统资源,因此,惰性删除策略对 CPU 时间最友好。
惰性删除策略的缺点:
- 如果一个 key 已经过期,而这个 key 又仍然保留在数据库中,那么只要这个过期 key 一直没有被访问,它所占用的内存就不会释放,造成了一定的内存空间浪费。所以,惰性删除策略对内存不友好。
定期删除策略是怎么样的?
定期删除策略的做法是,每隔一段时间「随机」从数据库中取出一定数量的 key 进行检查,并删除其中的过期key。
定期删除策略的优点:
- 通过限制删除操作执行的时长和频率,来减少删除操作对 CPU 的影响,同时也能删除一部分过期的数据减少了过期键对空间的无效占用。
定期删除策略的缺点:
- 内存清理方面没有定时删除效果好,同时没有惰性删除使用的系统资源少。
- 难以确定删除操作执行的时长和频率。如果执行的太频繁,定期删除策略变得和定时删除策略一样,对CPU不友好;如果执行的太少,那又和惰性删除一样了,过期 key 占用的内存不会及时得到释放。
Redis 过期删除策略是什么?
前面介绍了三种过期删除策略,每一种都有优缺点,仅使用某一个策略都不能满足实际需求。
所以, Redis 选择「惰性删除+定期删除」这两种策略配和使用,以求在合理使用 CPU 时间和避免内存浪费之间取得平衡。
Redis 是怎么实现惰性删除的?
Redis 的惰性删除策略由 db.c 文件中的 expireIfNeeded 函数实现,代码如下:
1 | int expireIfNeeded(redisDb *db, robj *key) { |
Redis 在访问或者修改 key 之前,都会调用 expireIfNeeded 函数对其进行检查,检查 key 是否过期:
- 如果过期,则删除该 key,至于选择异步删除,还是选择同步删除,根据
lazyfree_lazy_expire参数配置决定(Redis 4.0版本开始提供参数),然后返回 null 客户端; - 如果没有过期,不做任何处理,然后返回正常的键值对给客户端;
惰性删除的流程图如下:

Redis 是怎么实现定期删除的?
再回忆一下,定期删除策略的做法:每隔一段时间「随机」从数据库中取出一定数量的 key 进行检查,并删除其中的过期key。
这个间隔检查的时间是多长呢?
在 Redis 中,默认每秒进行 10 次过期检查一次数据库,此配置可通过 Redis 的配置文件 redis.conf 进行配置,配置键为 hz 它的默认值是 hz 10。
特别强调下,每次检查数据库并不是遍历过期字典中的所有 key,而是从数据库中随机抽取一定数量的 key 进行过期检查。
随机抽查的数量是多少呢?
我查了下源码,定期删除的实现在 expire.c 文件下的
activeExpireCycle函数中,其中随机抽查的数量由ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP定义的,它是写死在代码中的,数值是 20。也就是说,数据库每轮抽查时,会随机选择 20 个 key 判断是否过期。
接下来,详细说说 Redis 的定期删除的流程:
- 从过期字典中随机抽取 20 个 key;
- 检查这 20 个 key 是否过期,并删除已过期的 key;
- 如果本轮检查的已过期 key 的数量,超过 5 个(20/4),也就是「已过期 key 的数量」占比「随机抽取 key 的数量」大于 25%,则继续重复步骤 1;如果已过期的 key 比例小于 25%,则停止继续删除过期 key,然后等待下一轮再检查。
可以看到,定期删除是一个循环的流程。
那 Redis 为了保证定期删除不会出现循环过度,导致线程卡死现象,为此增加了定期删除循环流程的时间上限,默认不会超过 25ms。
针对定期删除的流程,我写了个伪代码:
1 | do { |
定期删除的流程如下:

从库是否会脏读到主键创建地过期键
阅读惰性删除和定期删除的源码阅读中,我们可以发现,从库对于主库的过期键是不能主动进行删除的。如果一个主库创建的过期键值对,已经过期了,主库在进行定期删除的时候,没有及时的删除掉,这时候从库请求了这个键值对,当执行惰性删除的时候,因为是主库创建的键值对,这时候是不能在从库中删除的,那么是不是就意味着从库会读取到已经过期的数据呢?
答案肯定不是的。
How Redis replication deals with expires on keys Redis expires allow keys to have a limited time to live. Such a feature depends on the ability of an instance to count the time, however Redis slaves correctly replicate keys with expires, even when such keys are altered using Lua scripts. To implement such a feature Redis cannot rely on the ability of the master and slave to have synchronized clocks, since this is a problem that cannot be solved and would result into race conditions and diverging data sets, so Redis uses three main techniques in order to make the replication of expired keys able to work: 1.Slaves don’t expire keys, instead they wait for masters to expire the keys. When a master expires a key (or evict it because of LRU), it synthesizes a DEL command which is transmitted to all the slaves. 2.However because of master-driven expire, sometimes slaves may still have in memory keys that are already logically expired, since the master was not able to provide the DEL command in time. In order to deal with that the slave uses its logical clock in order to report that a key does not exist only for read operations that don’t violate the consistency of the data set (as new commands from the master will arrive). In this way slaves avoid to report logically expired keys are still existing. In practical terms, an HTML fragments cache that uses slaves to scale will avoid returning items that are already older than the desired time to live. 3.During Lua scripts executions no keys expires are performed. As a Lua script runs, conceptually the time in the master is frozen, so that a given key will either exist or not for all the time the script runs. This prevents keys to expire in the middle of a script, and is needed in order to send the same script to the slave in a way that is guaranteed to have the same effects in the data set. Once a slave is promoted to a master it will start to expire keys independently, and will not require any help from its old master.
上面是官方文档中针对这一问题的描述
大概意思就是从节点不会主动删除过期键,从节点会等待主节点触发键过期。当主节点触发键过期时,主节点会同步一个del命令给所有的从节点。
因为是主节点驱动删除的,所以从节点会获取到已经过期的键值对。从节点需要根据自己本地的逻辑时钟来判断减值是否过期,从而实现数据集合的一致性读操作。
我们知道 Redis 中的过期策略是惰性删除和定期删除,所以每个键值的操作,都会使用惰性删除来检查是否过期,然后判断是否可以进行删除
1 | // https://github.com/redis/redis/blob/6.2/src/db.c#L1541 |
上面的惰性删除,对于主节点创建的过期 key ,虽然不能进行删除的操作,但是可以进行过期时间的判断,所以如果主库创建的过期键,如果主库没有及时进行删除,这时候从库可以通过惰性删除来判断键值对的是否过期,避免读取到过期的内容。
内存淘汰机制
前面说的过期删除策略,是删除已过期的 key,而当 Redis 的运行内存已经超过 Redis 设置的最大内存之后,则会使用内存淘汰策略删除符合条件的 key,以此来保障 Redis 高效的运行。
如何设置 Redis 最大运行内存?
在配置文件 redis.conf 中,可以通过参数 maxmemory <bytes> 来设定最大运行内存,只有在 Redis 的运行内存达到了我们设置的最大运行内存,才会触发内存淘汰策略。 不同位数的操作系统,maxmemory 的默认值是不同的:
- 在 64 位操作系统中,maxmemory 的默认值是 0,表示没有内存大小限制,那么不管用户存放多少数据到 Redis 中,Redis 也不会对可用内存进行检查,直到 Redis 实例因内存不足而崩溃也无作为。
- 在 32 位操作系统中,maxmemory 的默认值是 3G,因为 32 位的机器最大只支持 4GB 的内存,而系统本身就需要一定的内存资源来支持运行,所以 32 位操作系统限制最大 3 GB 的可用内存是非常合理的,这样可以避免因为内存不足而导致 Redis 实例崩溃。
Redis 淘汰机制有哪些?
Redis 内存淘汰策略共有八种,这八种策略大体分为「不进行数据淘汰」和「进行数据淘汰」两类策略。
1、不进行数据淘汰的策略
noeviction(Redis3.0之后,默认的内存淘汰策略) :它表示当运行内存超过最大设置内存时,不淘汰任何数据,这时如果有新的数据写入,会报错通知禁止写入,不淘汰任何数据,但是如果没用数据写入的话,只是单纯的查询或者删除操作的话,还是可以正常工作。
2、进行数据淘汰的策略
针对「进行数据淘汰」这一类策略,又可以细分为「在设置了过期时间的数据中进行淘汰」和「在所有数据范围内进行淘汰」这两类策略。
在设置了过期时间的数据中进行淘汰:
- volatile-random:随机淘汰设置了过期时间的任意键值;
- volatile-ttl:优先淘汰更早过期的键值。
- volatile-lru(Redis3.0 之前,默认的内存淘汰策略):淘汰所有设置了过期时间的键值中,最久未使用的键值;
- volatile-lfu(Redis 4.0 后新增的内存淘汰策略):淘汰所有设置了过期时间的键值中,最少使用的键值;
在所有数据范围内进行淘汰:
- allkeys-random:随机淘汰任意键值;
- allkeys-lru:淘汰整个键值中最久未使用的键值;
- allkeys-lfu(Redis 4.0 后新增的内存淘汰策略):淘汰整个键值中最少使用的键值。
如何查看当前 Redis 使用的内存淘汰策略?
可以使用 config get maxmemory-policy 命令,来查看当前 Redis 的内存淘汰策略,命令如下:
1 | 127.0.0.1:6379> config get maxmemory-policy |
可以看出,当前 Redis 使用的是 noeviction 类型的内存淘汰策略,它是 Redis 3.0 之后默认使用的内存淘汰策略,表示当运行内存超过最大设置内存时,不淘汰任何数据,但新增操作会报错。
如何修改 Redis 内存淘汰策略?
设置内存淘汰策略有两种方法:
- 方式一:通过“
config set maxmemory-policy <策略>”命令设置。它的优点是设置之后立即生效,不需要重启 Redis 服务,缺点是重启 Redis 之后,设置就会失效。 - 方式二:通过修改 Redis 配置文件修改,设置“
maxmemory-policy <策略>”,它的优点是重启 Redis 服务后配置不会丢失,缺点是必须重启 Redis 服务,设置才能生效。
内存淘汰算法
除了随机删除和不删除之外,主要有两种淘汰算法:LRU 算法和 LFU 算法。
LRU
LRU 全称是Least Recently Used译为最近最少使用,是一种常用的页面置换算法,选择最近最久未使用的页面予以淘汰。
一般 LRU 算法的实现基于链表结构,链表中的元素按照操作顺序从前往后排列,最新操作的键会被移动到表头,当需要内存淘汰时,只需要删除链表尾部的元素即可。
Redis 使用的是一种近似 LRU 算法,目的是为了更好的节约内存,它的实现方式是给现有的数据结构添加一个额外的字段,用于记录此键值的最后一次访问时间,Redis 内存淘汰时,会使用随机采样的方式来淘汰数据,它是随机取 5 个值(此值可配置),然后淘汰最久没有使用的那个。
如何实现?
Redis 在源码中对于每个键值对中的值,会使用一个 redisObject 结构体来保存指向值的指针,这里先来看下 redisObject 的结构
1 | // https://github.com/redis/redis/blob/6.2/src/server.h#L673 |
当一个键值对被创建的时候,就会记录下更新的时间
1 | // https://github.com/redis/redis/blob/6.2/src/object.c#L41 |
同时一个键值对被访问的时候记录的时间也会被更新,当一个键值对被访问时,访问操作最终都会调用 lookupKey 函数。
1 | // https://github.com/redis/redis/blob/6.2/src/db.c#L63 |
上面我们分别看了,创建和访问一个键值对的代码,每次操作,redisObject 中记录的 lru 时间就会被同步的更新
Redis 会判断当前内存的使用情况,如果超过了 maxmemory 配置的值,就会触发新的内存淘汰了
如果内存超过了 maxmemory 的值,这时候还需要去计算需要释放的内存量,这个释放的内存大小等于已使用的内存量减去 maxmemory。不过,已使用的内存量并不包括用于主从复制的复制缓冲区大小。
1 | // https://github.com/redis/redis/blob/6.2/src/evict.c#L512 |
处理淘汰的数据,Redis 中提供了一个数组 EvictionPoolLRU,用来保存待淘汰的候选键值对。这个数组的元素类型是 evictionPoolEntry 结构体,该结构体保存了待淘汰键值对的空闲时间 idle、对应的 key 等信息。
可以看到上面的上面会选取一定的过期键,然后插入到 EvictionPoolLRU 中
dictGetSomeKeys 函数采样的 key 的数量,是由 redis.conf 中的配置项 maxmemory-samples 决定的,该配置项的默认值是 5
1 | // https://github.com/redis/redis/blob/6.2/src/evict.c#L55 |
然后通过 evictionPoolPopulate 函数,进行采样,然后将采样数据写入到 EvictionPoolLRU 中,插入到 EvictionPoolLRU 中的数据是按照空闲时间从小到大进行排好序的
freeMemoryIfNeeded 函数会遍历一次 EvictionPoolLRU 数组,从数组的最后一个 key 开始选择,如果选到的 key 不是空值,那么就把它作为最终淘汰的 key。
1 | // https://github.com/redis/redis/blob/6.2/src/evict.c#L512 |
每次选中一部分过期的键值对,每次淘汰最久没有使用的那个,如果释放的内存空间还不够,就会重复的进行采样,删除的过程。
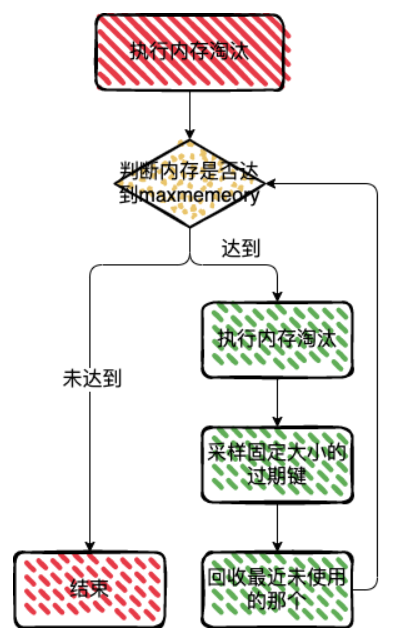
有问题吗?
LRU 算法有一个缺点,比如说很久没有使用的一个键值,如果最近被访问了一次,那么它就不会被淘汰,即使它是使用次数最少的缓存,那它也不会被淘汰,因此在 Redis 4.0 之后引入了 LFU 算法,下面我们一起来看。
LFU
LFU 全称是 Least Frequently Used 翻译为最不常用的,最不常用的算法是根据总访问次数来淘汰数据的,它的核心思想是“如果数据过去被访问多次,那么将来被访问的频率也更高”。
LFU 解决了偶尔被访问一次之后,数据就不会被淘汰的问题,相比于 LRU 算法也更合理一些。
上面分析 LRU 的时候,聊到了 redisObject,Redis 在源码中对于每个键值对中的值,会使用一个 redisObject 结构体来保存指向值的指针。里面 lru:LRU_BITS 字段记录了 LRU 算法和 LFU 算法需要的时间和计数器。
1 | typedef struct redisObject { |
Redis 对象头中的 lru 字段,在 LRU 算法下和 LFU 算法下使用方式并不相同。
在 LRU 算法中,Redis 对象头的 24 bits 的 lru 字段是用来记录 key 的访问时间戳,因此在 LRU 模式下,Redis可以根据对象头中的 lru 字段记录的值,来比较最后一次 key 的访问时间长,从而淘汰最久未被使用的 key。
在 LFU 算法中,Redis对象头的 24 bits 的 lru 字段被分成两段来存储,高 16bit 存储 ldt(Last Decrement Time),低 8bit 存储 logc(Logistic Counter)。

- ldt 是用来记录 key 的访问时间戳;
- logc 是用来记录 key 的访问频次,它的值越小表示使用频率越低,越容易淘汰,每个新加入的 key 的logc 初始值为 5。
logc 并不是单纯的访问次数,而是访问频次(访问频率),因为 logc 会随时间推移而衰减的。
在每次 key 被访问时,会先对 logc 做一个衰减操作,衰减的值跟前后访问时间的差距有关系,如果上一次访问的时间与这一次访问的时间差距很大,那么衰减的值就越大,这样实现的 LFU 算法是根据访问频率来淘汰数据的,而不只是访问次数。访问频率需要考虑 key 的访问是多长时间段内发生的。key 的先前访问距离当前时间越长,那么这个 key 的访问频率相应地也就会降低,这样被淘汰的概率也会更大。
对 logc 做完衰减操作后,就开始对 logc 进行增加操作,增加操作并不是单纯的 + 1,而是根据概率增加,如果 logc 越大的 key,它的 logc 就越难再增加。
1 | // https://github.com/redis/redis/blob/6.2/src/evict.c#L298 |
如果当前访问次数小于255的时候,每次 LFULogIncr 函数会计算一个阈值 p,以及一个取值为 0 到 1 之间的随机概率值 r。如果概率 r 小于阈值 p,那么 LFULogIncr 函数才会将logc 加 1。否则的话,LFULogIncr 函数会返回当前的logc ,不做更新。
所以,Redis 在访问 key 时,对于 logc 是这样变化的:
- 先按照上次访问距离当前的时长,来对 logc 进行衰减;
- 然后,再按照一定概率增加 logc 的值
redis.conf 提供了两个配置项,用于调整 LFU 算法从而控制 logc 的增长和衰减:
lfu-decay-time用于调整 logc 的衰减速度,它是一个以分钟为单位的数值,默认值为1,lfu-decay-time值越大,衰减越慢;lfu-log-factor用于调整 logc 的增长速度,lfu-log-factor值越大,logc 增长越慢。
使用 LFU 算法淘汰数据
LFU 处理数据淘汰和 LRU 方式差不多,这里回顾下 LRU 处理数据淘汰的过程
- 1、调用 getMaxmemoryState 函数计算待释放的内存空间;
- 2、调用 evictionPoolPopulate 函数随机采样键值对,并插入到待淘汰集合 EvictionPoolLRU 中;
- 3、遍历待淘汰集合 EvictionPoolLRU,选择实际被淘汰数据,并删除。
不同的是,LFU 算法在淘汰数据时,在第二步的 evictionPoolPopulate 函数中,使用了不同的方法来计算每个待淘汰键值对的空闲时间。
LRU 中 idle 记录的是它距离上次访问的空闲时间。
LFU 中 idle 记录的是用 255 减去键值对的 logc。也就是键值对访问次数越大,它的 idle 值就越小,反之 idle 值越大。
freeMemoryIfNeeded 函数按照 idle 值从大到小,遍历 EvictionPoolLRU 数组,选择实际被淘汰的键值对时,它就能选出访问次数小的键值对了,也就是把访问频率低的键值对淘汰出去。
为什么数据删除后内存占用还是很高?
Redis 中的内存可能会遇到这样一种情况,虽然进行了数据的删除,数据量已经不大了,但是使用 top 命令,发现 Redis 还是会占用大量的内存
因为,当数据删除后,Redis 释放的内存空间会由内存分配器管理,并不会立即返回给操作系统。所以,操作系统仍然会记录着给 Redis 分配了大量内存。
但是这些内存可能是不连续的,对于不连续的小内存块,虽然是空闲内存,但是 Redis 却不能拿来用,会造成资源的浪费。
为什么会产生内存碎片呢?
内存碎片如何产生?
1、内存分配器的分配策略
内存分配器对于内存的分配,一般是按固定大小来分配内存,而不是完全按照应用程序申请的内存空间大小给程序分配。
Redis 可以使用 libc、jemalloc、tcmalloc 多种内存分配器来分配内存,默认使用 jemalloc。
jemalloc 的分配策略之一,是按照一系列固定的大小划分内存空间,例如8字节、16字节、32字节、48字节,…, 2KB、4KB、8KB等。当程序申请的内存最接近某个固定值时,jemalloc会给它分配相应大小的空间。
这样的分配方式本身是为了减少分配次数。例如,Redis申请一个20字节的空间保存数据,jemalloc 就会分配 32 字节,此时,如果应用还要写入 10 字节的数据,Redis 就不用再向操作系统申请空间了,因为刚才分配的32字节已经够用了,这就避免了一次分配操作。
减少了内存分配的次数,缺点就是增加了产生内存碎片的可能。
2、键值对的删除更改操作
Redis 中键值对会被修改和删除,这会导致空间的扩容和释放,一方面,如果修改后的键值对变大或变小了,就需要占用额外的空间或者释放不用的空间。另一方面,删除的键值对就不再需要内存空间了,此时,就会把空间释放出来,形成空闲空间。
Redis中的值删除的时候,并没有把内存直接释放,交还给操作系统,而是交给了Redis内部有内存管理器。
Redis 中申请内存的时候,也是先看自己的内存管理器中是否有足够的内存可用。Redis的这种机制,提高了内存的使用率,但是会使 Redis 中有部分自己没在用,却不释放的内存,导致了内存碎片的发生。
碎片率的意义
mem_fragmentation_ratio的不同值,说明不同的情况。
- 大于1:说明内存有碎片,一般在1到1.5之间是正常的;
- 大于1.5:说明内存碎片率比较大,需要考虑是否要进行内存碎片清理,要引起重视;
- 小于1:说明已经开始使用交换内存,也就是使用硬盘了,正常的内存不够用了,需要考虑是否要进行内存的扩容。
可以使用 INFO memory 命令查看内存碎片率
1 | 127.0.0.1:6379> INFO memory |
mem_fragmentation_ratio 表示的就是内存碎片率
1 | mem_fragmentation_ratio = used_memory_rss/ used_memory |
used_memory_rss 是操作系统实际分配给 Redis 的物理内存空间,里面就包含了碎片;而 used_memory 是 Redis 为了保存数据实际申请使用的空间。
如何清理内存碎片?
Redis服务器重启后,Redis会将没用的内存归还给操作系统,碎片率会降下来;
4.0 版本的 Redis 引入了自动内存碎片清理的功能。
自动碎片清理,只要设置了如下的配置,内存就会自动清理了。
1 | config set activedefrag yes |
不过对于具体什么时候开始,受下面两个参数的控制,只要一个不满足就停止自动清理
- active-defrag-ignore-bytes 100mb:表示内存碎片的字节数达到100MB时,开始清理;
- active-defrag-threshold-lower 10:表示内存碎片空间占操作系统分配给Redis的总空间比例达到10%时,开始清理。
为了保证清理过程中对 CPU 的影响,还设置了两个参数,分别用于控制清理操作占用的CPU时间比例的上、下限,既保证清理工作能正常进行,又避免了降低Redis性能。
- active-defrag-cycle-min 25: 表示自动清理过程所用CPU时间的比例不低于25%,保证清理能正常开展;
- active-defrag-cycle-max 75:表示自动清理过程所用CPU时间的比例不高于75%,一旦超过,就停止清理,从而避免在清理时,大量的内存拷贝阻塞Redis,导致响应延迟升高。
如果你对自动清理的效果不满意,可以使用如下命令,直接试下手动碎片清理:
1 | memory purge |
总结
Redis 使用的过期删除策略是「惰性删除+定期删除」,删除的对象是已过期的 key。

内存淘汰策略是解决内存过大的问题,当 Redis 的运行内存超过最大运行内存时,就会触发内存淘汰策略,Redis 4.0 之后共实现了 8 种内存淘汰策略,我也对这 8 种的策略进行分类,如下:

Redis 一切操作都是为了保证高效、灵活地利用内存,提供飞快的读写速度。希望你看完这篇文章,对 Redis 的键值过期操作和内存淘汰机制有了一个轻松愉快的了解。记住,Redis 虽然是个内存管理高手,但也需要你合理设置过期时间和选择合适的淘汰策略,这样才能愉快地玩耍下去!
更加深入的东西还是需要通过源码来进行学习,仅仅通过别人的博客还是学不到深入的内容。