
Redis家族再添新成员:探索Bitmaps、HyperLogLog和Geo的魅力
在之前的博客中,我们已经学习了 Redis 中的五种基础数据结构和六种底层数据结构。随着 Redis 在江湖上的名气越来越大,又有不少的英雄豪杰加入了 Redis 这一大帮派。
这个家族又迎来了三位新的成员:Bitmaps、HyperLogLog 和 Geo,三者各怀绝技,进一步巩固了Redis在数据江湖中的地位。
接下来就让我们来看一下这三位的实力把。
Bitmaps :位操作的巧匠
根据官网介绍:
Bitmaps are not an actual data type, but a set of bit-oriented operations defined on the String type which is treated like a bit vector. Since strings are binary safe blobs and their maximum length is 512 MB, they are suitable to set up to 2^32 different bits.
Bitmap 不是 Redis 中的实际数据类型,而是在 String 类型上定义的一组面向位的操作,将其视为位向量。由于字符串是二进制安全的块,且最大长度为 512 MB,它们适合用于设置最多 2^32 个不同的位。
Bitmap 即位图数据结构,都是操作二进制位来进行记录,只有0 和 1 两个状态。
用来解决什么问题?
思考一个问题,在一个场景下,我们需要存储大规模的布尔数据类型,比如用户的签到信息、用户是否在线、某个时间段用户是否观看了某个视频等等。使用传统的数据结构可能会消耗大量的内存。
那要怎么实现我们想要的功能?
使用 Bitmaps 。bitmap 最大的优势之一是存储信息时,它经常可以极大的节省空间。例如,一个用户的系统中,使用递增的 id 来表示不同的用户,这时候 bitmap 使用 512MB 内存就可以记录 40 亿用户的一个比特信息(例如,1是男生,0是女生,一个男生的id为19,那么这个 bitmap 的第 19 位就是 1)。
介绍
Bitmap 存储的是连续的二进制数字(0 和 1),通过 Bitmap, 只需要一个 bit 位来表示某个元素对应的值或者状态,key 就是对应元素本身 。我们知道 8 个 bit 可以组成一个 byte,所以 Bitmap 本身会极大的节省储存空间。
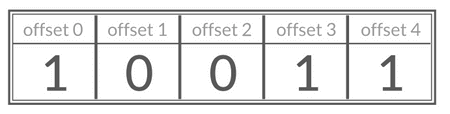
你可以将 Bitmap 看作是一个存储二进制数字(0 和 1)的数组,数组中每个元素的下标叫做 offset(偏移量)。
常用命令
| 命令 | 介绍 |
|---|---|
| SETBIT key offset value | 设置指定 offset 位置的值 |
| GETBIT key offset | 获取指定 offset 位置的值 |
| BITCOUNT key start end | 获取 start 和 end 之前值为 1 的元素个数 |
| BITOP operation destkey key1 key2 … | 对一个或多个 Bitmap 进行运算,可用运算符有 AND, OR, XOR 以及 NOT |
使用
使用bitmap 来记录 周一到周日的打卡! 周一:1 周二:0 周三:0 周四:1 ……
1 | 127.0.0.1:6379> setbit sign 0 1 |
查看某一天是否有打卡!
1 | 127.0.0.1:6379> getbit sign 3 |
统计操作,统计 打卡的天数!
1 | 127.0.0.1:6379> bitcount sign # 统计这周的打卡记录,就可以看到是否有全勤! |
应用场景
需要保存状态信息(0/1 即可表示)的场景
- 举例:用户签到情况、活跃用户情况、用户行为统计(比如是否点赞过某个视频)。
- 相关命令:
SETBIT、GETBIT、BITCOUNT、BITOP。
HyperLogLog:基数估计的神算
为什么要使用 HyperLogLog
在我们实际开发的过程中,可能会遇到这样一个问题,当我们需要统计一个大型网站的独立访问次数时,该用什么的类型来统计?
如果我们使用 Redis 中的集合来统计,当它每天有数千万级别的访问时,将会是一个巨大的问题。因为这些访问量不能被清空,我们运营人员可能会随时查看这些信息,那么随着时间的推移,这些统计数据所占用的空间会越来越大,逐渐超出我们能承载最大空间。
例如,我们用 IP 来作为独立访问的判断依据,那么我们就要把每个独立 IP 进行存储,以 IP4 来计算,IP4 最多需要 15 个字节来存储信息,例如:110.110.110.110。当有一千万个独立 IP 时,所占用的空间就是 15 bit*10000000 约定于 143MB,但这只是一个页面的统计信息,假如我们有 1 万个这样的页面,那我们就需要 1T 以上的空间来存储这些数据,而且随着 IP6 的普及,这个存储数字会越来越大,那我们就不能用集合的方式来存储了,这个时候我们需要开发新的数据类型 HyperLogLog 来做这件事了。
介绍
HyperLogLog(下文简称为 HLL)是 Redis 2.8.9 版本添加的数据结构,它用于高性能的基数(去重)统计功能,它的缺点就是存在极低的误差率。
HLL 具有以下几个特点:
- 能够使用极少的内存来统计巨量的数据,它只需要 12K 空间就能统计 2^64 的数据;
- 统计存在一定的误差,误差率整体较低,标准误差为 0.81%;
- 误差可以被设置辅助计算因子进行降低。
Redis 对 HyperLogLog 的存储结构做了优化,采用两种方式计数:
- 稀疏矩阵:计数较少的时候,占用空间很小。
- 稠密矩阵:计数达到某个阈值的时候,占用 12k 的空间。
基本使用
HLL 的命令只有 3 个,但都非常的实用,下面分别来看。
添加元素
1 | 127.0.0.1:6379> pfadd key "redis" |
相关语法:
1 | pfadd key element [element ...] |
此命令支持添加一个或多个元素至 HLL 结构中。
统计不重复的元素
1 | 127.0.0.1:6379> pfadd key "redis" |
从 pfcount 的结果可以看出,在 HLL 结构中键值为 key 的元素,有 2 个不重复的值:redis 和 sql,可以看出结果还是挺准的。
相关语法:
1 | pfcount key [key ...] |
此命令支持统计一个或多个 HLL 结构。
合并一个或多个 HLL 至新结构
新增 k 和 k2 合并至新结构 k3 中,代码如下:
1 | 127.0.0.1:6379> pfadd k "java" "sql" |
相关语法:
1 | pfmerge destkey sourcekey [sourcekey ...] |
pfmerge 使用场景
当我们需要合并两个或多个同类页面的访问数据时,我们可以使用 pfmerge 来操作。
代码实战
接下来我们使用 Java 代码来实现 HLL 的三个基础功能,代码如下:
1 | import redis.clients.jedis.Jedis; |
以上代码执行结果如下:
1 | k:2 |
算法原理
HyperLogLog 算法来源于论文 HyperLogLog the analysis of a near-optimal cardinality estimation algorithm,想要了解 HLL 的原理,先要从伯努利试验说起,伯努利实验说的是抛硬币的事。一次伯努利实验相当于抛硬币,不管抛多少次只要出现一个正面,就称为一次伯努利实验。
我们用 k 来表示每次抛硬币的次数,n 表示第几次抛的硬币,用 k_max 来表示抛硬币的最高次数,最终根据估算发现 n 和 k_max 存在的关系是 n=2^(k_max),但同时我们也发现了另一个问题当试验次数很小的时候,这种估算方法的误差会很大,例如我们进行以下 3 次实验:
- 第 1 次试验:抛 3 次出现正面,此时 k=3,n=1;
- 第 2 次试验:抛 2 次出现正面,此时 k=2,n=2;
- 第 3 次试验:抛 6 次出现正面,此时 k=6,n=3。
对于这三组实验来说,k_max=6,n=3,但放入估算公式明显 3≠2^6。为了解决这个问题 HLL 引入了分桶算法和调和平均数来使这个算法更接近真实情况。
分桶算法是指把原来的数据平均分为 m 份,在每段中求平均数在乘以 m,以此来消减因偶然性带来的误差,提高预估的准确性,简单来说就是把一份数据分为多份,把一轮计算,分为多轮计算。
而调和平均数指的是使用平均数的优化算法,而非直接使用平均数。
例如小明的月工资是 1000 元,而小王的月工资是 100000 元,如果直接取平均数,那小明的平均工资就变成了 (1000+100000)/2=50500 元,这显然是不准确的,而使用调和平均数算法计算的结果是 2/(1⁄1000+1⁄100000)≈1998 元,显然此算法更符合实际平均数。
所以综合以上情况,在 Redis 中使用 HLL 插入数据,相当于把存储的值经过 hash 之后,再将 hash 值转换为二进制,存入到不同的桶中,这样就可以用很小的空间存储很多的数据,统计时再去相应的位置进行对比很快就能得出结论,这就是 HLL 算法的基本原理,想要更深入的了解算法及其推理过程,可以看去原版的论文。
应用场景
数量量巨大(百万、千万级别以上)的计数场景
- 举例:热门网站每日/每周/每月访问 ip 数统计、热门帖子 uv 统计、
- 相关命令:
PFADD、PFCOUNT。
Geo:地理位置的游侠
受过高等教育的我们都知道,我们所处的任何位置都可以用经度和纬度来标识,经度的范围 -180 到 180,纬度的范围为 -90 到 90。纬度以赤道为界,赤道以南为负数,赤道以北为正数;经度以本初子午线(英国格林尼治天文台)为界,东边为正数,西边为负数。
Redis 在 3.2 版本中增加了 GEO 类型用于存储和查询地理位置,GEO 本质上是基于 ZSet 实现的。
关于 GEO 的命令不多,主要包含以下 6 个:
- geoadd:添加地理位置
- geopos:查询位置信息
- geodist:距离统计
- georadius:查询某位置内的其他成员信息
- geohash:查询位置的哈希值
- zrem:删除地理位置
下面我们分别来看这些命令的使用。
使用
添加地理位置
我们先用百度地图提供的经纬度查询工具,地址:
如下图所示:
找了以下 4 个地点,添加到 Redis 中:
- 天安门:116.404269,39.913164
- 月坛公园:116.36,39.922461
- 北京欢乐谷:116.499705,39.874635
- 香山公园:116.193275,39.996348
代码如下:
1 | 127.0.0.1:6379> geoadd site 116.404269 39.913164 tianan |
相关语法:
1 | geoadd key longitude latitude member [longitude latitude member ...] |
重点参数说明如下:
- longitude 表示经度
- latitude 表示纬度
- member 是为此经纬度起的名字
此命令支持一次添加一个或多个位置信息。
查询位置信息
1 | 127.0.0.1:6379> geopos site tianan |
相关语法:
1 | geopos key member [member ...] |
此命令支持查看一个或多个位置信息。
距离统计
1 | 127.0.0.1:6379> geodist site tianan yuetan km |
可以看出天安门距离月坛公园的直线距离大概是 3.9 km,我们打开地图使用工具测试一下咱们的统计结果是否准确,如下图所示:
可以看出 Redis 的统计和使用地图工具统计的距离是完全吻合的。
注意:此命令统计的距离为两个位置的直线距离。
相关语法:
1 | geodist key member1 member2 [unit] |
unit 参数表示统计单位,它可以设置以下值:
- m:以米为单位,默认单位;
- km:以千米为单位;
- mi:以英里为单位;
- ft:以英尺为单位。
查询某位置内的其他成员信息
1 | 127.0.0.1:6379> georadius site 116.405419 39.913164 5 km |
此命令的意思是查询天安门(116.405419,39.913164)附近 5 公里范围内的成员列表。
相关语法:
1 | georadius key longitude latitude radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC] |
可选参数说明如下。
1. WITHCOORD
说明:返回满足条件位置的经纬度信息。
示例代码:
1 | 127.0.0.1:6379> georadius site 116.405419 39.913164 5 km withcoord |
2. WITHDIST
说明:返回满足条件位置与查询位置的直线距离。
示例代码:
1 | 127.0.0.1:6379> georadius site 116.405419 39.913164 5 km withdist |
3. WITHHASH
说明:返回满足条件位置的哈希信息。
示例代码:
1 | 127.0.0.1:6379> georadius site 116.405419 39.913164 5 km withhash |
4. COUNT count
说明:指定返回满足条件位置的个数。
例如,指定返回一条满足条件的信息,代码如下:
1 | 127.0.0.1:6379> georadius site 116.405419 39.913164 5 km count 1 |
5. ASC|DESC
说明:从近到远|从远到近排序返回。
示例代码:
1 | 127.0.0.1:6379> georadius site 116.405419 39.913164 5 km desc |
当然以上这些可选参数也可以一起使用,例如以下代码:
1 | 127.0.0.1:6379> georadius site 116.405419 39.913164 5 km withdist desc |
5. 查询哈希值
1 | 127.0.0.1:6379> geohash site tianan |
相关语法:
1 | geohash key member [member ...] |
此命令支持查询一个或多个地址的哈希值。
6. 删除地理位置
1 | 127.0.0.1:6379> zrem site xiaoming |
相关语法:
1 | zrem key member [member ...] |
此命令支持删除一个或多个位置信息。
代码实战
下面我们用 Java 代码,来实现查询附近的人,完整代码如下:
1 | import redis.clients.jedis.GeoCoordinate; |
以上程序执行的结果如下:
1 | 小明和小红相距:3.9153 KM |
应用场景
Redis 中的 GEO 经典使用场景如下:
- 查询附近的人、附近的地点等;
- 计算相关的距离信息。
总结
以上是 Redis 后续新增的三种数据结构的介绍和基本使用方法。在实际开发中,我们要实现的很多功能其实都要用到这三种数据结构。其实博客项目看似好像是一个烂大街的玩具,但其实如果真的要开发一款能推向市场的博客系统,还是要费很大的功夫的。
越往深处学就会发现它们的应用就在我们身边,这可能就是计算机不好入行的原因吧,刚开始学的全是一些抽象的东西,想要去实现一个我们平常使用的功能基本是不可能的,只有在深入学习各种框架、技术之后才能更好地理解身边的技术实现。
今天写的这几篇博客其实都有一点抽象,主要是因为之前在学 Redis 时,因为刚入门,所以很多东西都要去深入学习,最近几天看到的内容都是一个功能的实现,没有深挖的内容,所以在记录博客时就直接照着别人的总结写了一遍。你说这有用吗,应该比直接看一遍有用。
这两天都在学 Java 的基础知识,感觉和 Go 差的太多了,很麻烦,东西很杂。昨晚想通了一个问题,既然决定直接备战秋招了,时间还有差不多两三个月,其实可以不用那么急躁,囫囵吞枣式的学习只会带来更快的遗忘。
参考
https://javaguide.cn/database/redis/redis-data-structures-02.html
https://pdai.tech/md/db/nosql-redis/db-redis-data-type-special.html