
Redis消息队列:你的数据,随时待命
现如今的互联网应用大多是采用分布式系统机构设计的,所以消息队列已经逐渐成为企业应用系统内部通信的核心手段,它具有低耦合、可靠投递、广播、流量控制、最终一致性等一系列功能。
当前使用较多的 消息队列 有 RabbitMQ、RocketMQ、ActiveMQ、Kafka、ZeroMQ、MetaMQ 等,而部分数据库如 Redis、MySQL 以及 phxsql ,如果硬搞的话,其实也可实现消息队列的功能。
可能有人觉得,各种开源的 MQ 已经足够使用了,为什么需要用 Redis 实现 MQ 呢?
有些简单的业务场景,可能不需要重量级的 MQ 组件(相比 Redis 来说,Kafka 和 RabbitMQ 都算是重量级的消息队列)
那你有考虑过用 Redis 做消息队列吗?
这一章,我会结合消息队列的特点和 Redis 做消息队列的使用方式,以及实际项目中的使用,来探讨下 Redis 消息队列的方案。
消息队列是什么?
消息队列是指利用高效可靠的消息传递机制进行与平台无关的数据交流,并基于数据通信来进行分布式系统的集成。
通过提供消息传递和消息排队模型,它可以在分布式环境下提供 应用解耦、弹性伸缩、冗余存储、流量削峰、异步通信、数据同步 等等功能,其作为分布式系统架构中的一个重要组件,有着举足轻重的地位。
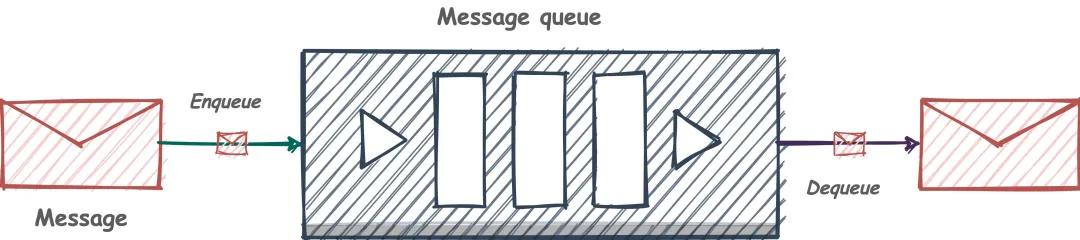
现在回顾一下,我们使用的消息队列一般有什么样的特点:
- 三个角色:生产者、消费者 和 消息处理中心。
- 异步处理模式:生产者将消息发送到一条虚拟的通道(消息队列)上,而无需等待响应。消费者则订阅或是监听该通道,取出消息。两者互不干扰,甚至都不用同时在线,也就是我们说的松耦合。
- 可靠性:消息要可以保证不丢失、不重复消费、有时可能还需要顺序性的保证。
撇开我们常用的消息中间件不说, Redis 的哪些数据类型可以满足 MQ 的常规需求~~
Redis 如何实现消息队列?
思来想去,也就只有 List 和 Stream 两种数据类型,可以实现消息队列的这些需求,当然,Redis 还提供了 发布/订阅(pub/sub) 模式。
下面我们一一来看。
List 实现消息队列
Redis 列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)。
所以常用来做异步队列使用。将需要延后处理的任务结构体序列化成字符串塞进 Redis 的列表,另一个线程从这个列表中轮询数据进行处理。
List 使用命令的方式实现消息队列:
1 | 127.0.0.1:6379> lpush mq "hello" #推送消息 hello |
其中,mq 就相当于频道名称 channel,而 lpush 用于生产消息, rpop 拉取消息。
代码实现
接下来我们用 Java 代码的方式来实现 List 形式的消息队列,源码如下:
1 | import redis.clients.jedis.Jedis; |
以上程序的运行结果是:
1 | 接收到消息:Hello, List. |
我们使用无限循环来获取队列中的数据,这样就可以实时地获取相关信息了,但这样会带来另一个新的问题,当队列中如果没有数据的情况下,无限循环会一直消耗系统的资源,这时候我们可以使用 brpop 替代 rpop 来完美解决这个问题。
b 是 blocking 的缩写,表示阻塞读,也就是当队列没有数据时,它会进入休眠状态,当有数据进入队列之后,它才会“苏醒”过来执行读取任务,这样就可以解决 while 循环一直执行消耗系统资源的问题了,改良版代码如下:
1 | import redis.clients.jedis.Jedis; |
其中,brpop() 方法的第一个参数是设置超时时间的,设置 0 表示一直阻塞。
可靠队列模式 | ack 机制
以上方式中, List 队列中的消息一经发送出去,便从队列里删除。如果由于网络原因消费者没有收到消息,或者消费者在处理这条消息的过程中崩溃了,就再也无法还原出这条消息。究其原因,就是缺少消息确认机制。
为了保证消息的可靠性,消息队列都会有完善的消息确认机制(Acknowledge),即消费者向队列报告消息已收到或已处理的机制。
Redis List 怎么搞一搞呢?
有两个命令, RPOPLPUSH、BRPOPLPUSH (阻塞)从一个 list 中获取消息的同时把这条消息复制到另一个 list 里(可以当做备份),而且这个过程是原子的。
这样我们就可以在业务流程安全结束后,再删除队列元素,实现消息确认机制。
1 | 127.0.0.1:6379> rpush myqueue one |
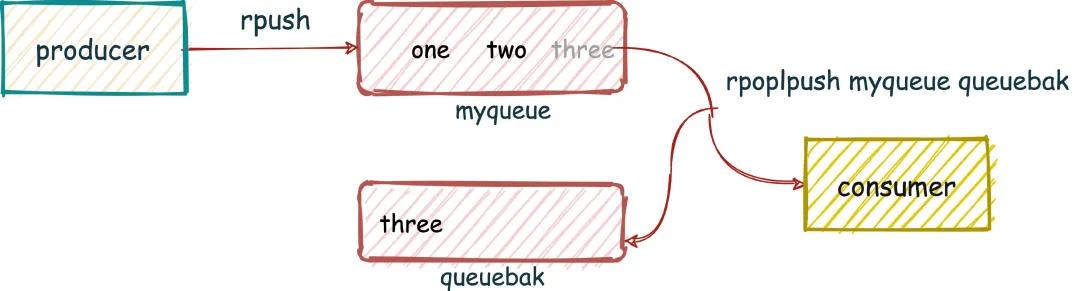
之前做过的项目中就有用到这样的方式去处理数据,数据标识从一个 List 取出后放入另一个 List,业务操作安全执行完成后,再去删除 List 中的数据,如果有问题的话,很好回滚。
当然,还有更特殊的场景,可以通过 zset 来实现延时消息队列,原理就是将消息加到 zset 结构后,将要被消费的时间戳设置为对应的 score 即可,只要业务数据不会是重复数据就 OK。
优缺点分析
List 优点:
- 消息可以被持久化,借助 Redis 本身的持久化(AOF、RDB 或者是混合持久化),可以有效的保存数据;
- 消费者可以积压消息,不会因为客户端的消息过多而被强行断开。
List 缺点:
- 消息不能被重复消费,一个消息消费完就会被删除;
- 没有主题订阅的功能。
ZSet 优点:
- 支持消息持久化;
- 相比于 List 查询更方便,ZSet 可以利用 score 属性很方便的完成检索,而 List 则需要遍历整个元素才能检索到某个值。
ZSet 缺点:
- ZSet 不能存储相同元素的值,也就是如果有消息是重复的,那么只能插入一条信息在有序集合中;
- ZSet 是根据 score 值排序的,不能像 List 一样,按照插入顺序来排序;
- ZSet 没有向 List 的 brpop 那样的阻塞弹出的功能。
订阅与发布实现消息队列
我们都知道消息模型有两种
- 点对点:Point-to-Point(P2P)
- 发布订阅:Publish/Subscribe(Pub/Sub)
List 实现方式其实就是点对点的模式,下边我们再看下 Redis 的发布订阅模式(消息多播),这才是“根正苗红”的 Redis MQ。
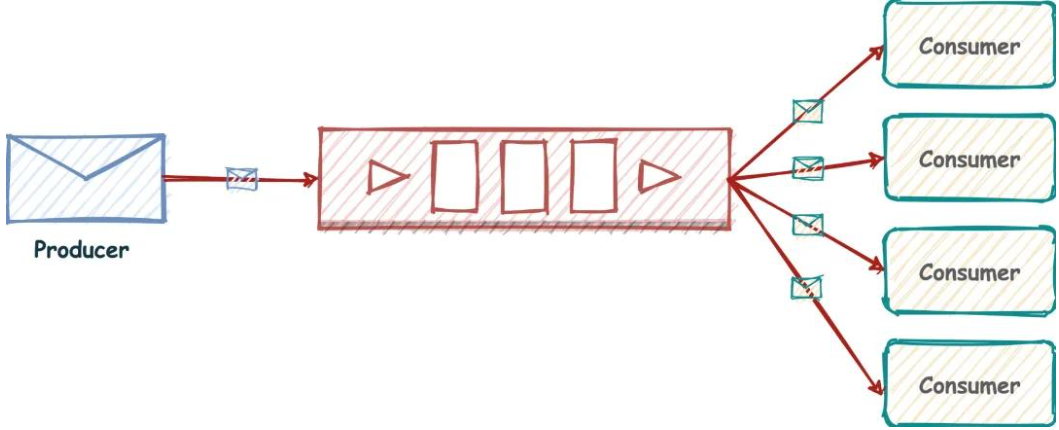
普通订阅与发布
消息队列有两个重要的角色,一个是发送者,另一个就是订阅者,对应的命令如下:
- 发布消息:publish channel “message”
- 订阅消息:subscribe channel
下面我们来看具体的命令实现。
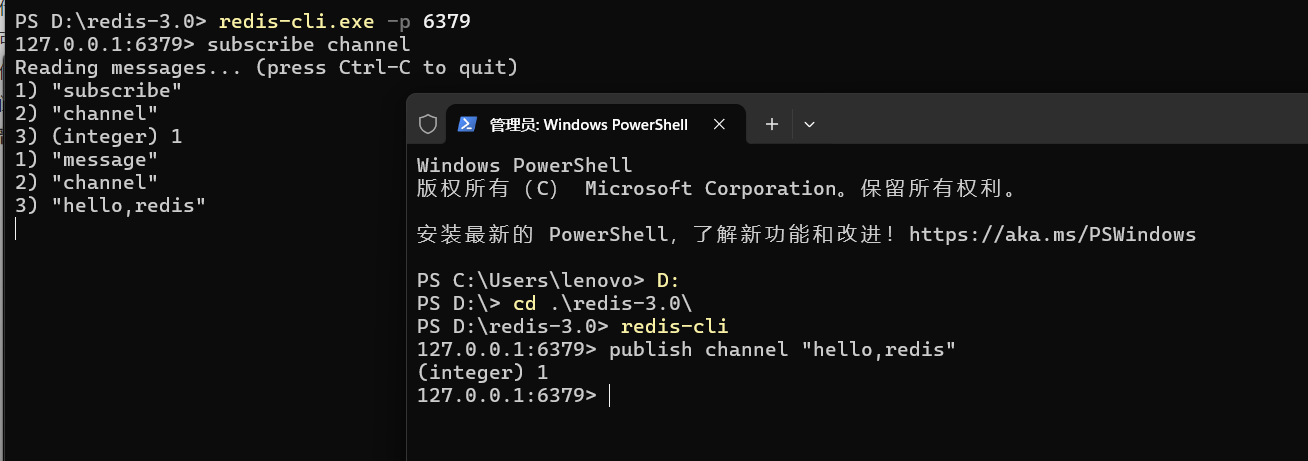
上方订阅频道 channel,下方在频道 channel 中发布消息。
此命令支持订阅一个或多个频道的命令,也就是说一个订阅者可以订阅多个频道。
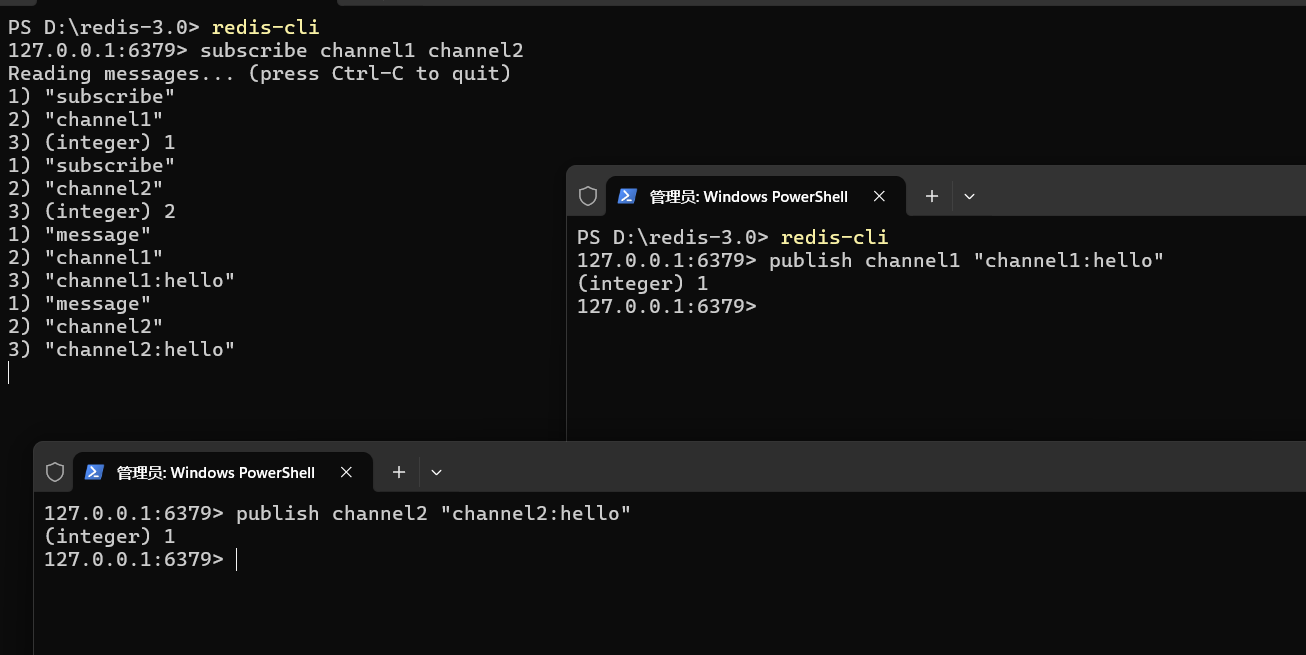
订阅消息:
1 | subscribe channel [channel ...] |
发送消息:
1 | publish channel message |
最后的返回值表示成功发送给几个订阅方,1 表示成功发给了一个订阅者,这个数字可以是 0~n,这是由订阅者的数量决定的。
主题订阅
上面介绍了普通的订阅与发布模式,但如果我要订阅某一个类型的消息就不适用了,例如我要订阅日志类的消息队列,它们的命名都是 logXXX,这个时候就需要使用 Redis 提供的另一个功能 Pattern Subscribe 主题订阅,这种方式可以使用 * 来匹配多个频道,如下图所示:
主题模式的具体实现代码如下,订阅者:
1 | 127.0.0.1:6379> psubscribe log_* #主题订阅 log_* |
从上面的运行结果,可以看出使用命令 psubscribe log_* 可以接收到所有频道包含 log_XXX 的消息。
相关语法:
1 | psubscribe pattern [pattern ...] |
生产者的代码如下:
1 | 127.0.0.1:6379> publish log_user "user message." |
代码实现
下面我们使用 Jedis 实现普通的发布订阅模式和主题订阅的功能。
普通模式
消费者代码如下:
1 | /** |
生产者代码如下:
1 | /** |
发布者和订阅者模式运行:
1 | public static void main(String[] args) throws InterruptedException { |
以上代码运行结果如下:
1 | 频道 channel 收到消息:Hello, channel. |
主题订阅模式
主题订阅模式的生产者的代码是一样,只有消费者的代码是不同的,如下所示:
1 | /** |
主题模式运行代码如下:
1 | public static void main(String[] args) throws InterruptedException { |
以上代码运行结果如下:
1 | channel* 主题 | 频道 channel 收到消息:Hello, channel. |
注意事项
发布订阅模式存在以下两个缺点:
- 无法持久化保存消息,如果 Redis 服务器宕机或重启,那么所有的消息将会丢失;
- 发布订阅模式是“发后既忘”的工作模式,如果有订阅者离线重连之后不能消费之前的历史消息。
然而这些缺点在 Redis 5.0 添加了 Stream 类型之后会被彻底的解决。
除了以上缺点外,发布订阅模式还有另一个需要注意问题:当消费端有一定的消息积压时,也就是生产者发送的消息,消费者消费不过来时,如果超过 32M 或者是 60s 内持续保持在 8M 以上,消费端会被强行断开,这个参数是在配置文件中设置的,默认值是 client-output-buffer-limit pubsub 32mb 8mb 60。
Pub/Sub 常用命令:
| 命令 | 用法 | 描述 |
|---|---|---|
| PSUBSCRIBE | PSUBSCRIBE pattern [pattern …] | 订阅一个或多个符合给定模式的频道 |
| PUBSUB | PUBSUB subcommand [argument [argument …]] | 查看订阅与发布系统状态 |
| PUBLISH | PUBLISH channel message | 将信息发送到指定的频道 |
| PUNSUBSCRIBE | PUNSUBSCRIBE [pattern [pattern …]] | 退订所有给定模式的频道 |
| SUBSCRIBE | SUBSCRIBE channel [channel …] | 订阅给定的一个或多个频道的信息 |
| UNSUBSCRIBE | UNSUBSCRIBE [channel [channel …]] | 指退订给定的频道 |
Stream 实现消息队列
在 Redis 5.0 Stream 没出来之前,消息队列的实现方式都有着各自的缺陷,例如:
- 发布订阅模式 PubSub,不能持久化也就无法可靠的保存消息,并且对于离线重连的客户端不能读取历史消息的缺陷;
- 列表实现消息队列的方式不能重复消费,一个消息消费完就会被删除;
- 有序集合消息队列的实现方式不能存储相同 value 的消息,并且不能阻塞读取消息。
并且以上三种方式在实现消息队列时,只能存储单 value 值,也就是如果你要存储一个对象的情况下,必须先序列化成 JSON 字符串,在读取之后还要反序列化成对象才行,这也给用户的使用带来的不便,基于以上问题,Redis 5.0 便推出了 Stream 类型也是此版本最重要的功能,用于完美地实现消息队列,它借鉴了 Kafka 的设计思路,它支持消息的持久化和消息轨迹的消费,支持 ack 确认消息的模式,让消息队列更加的稳定和可靠。
接下来我们先来了解 Stream 自身的一些特性,然后在综合 Stream 的特性,结合 Java 代码完整的实现一个完美的消息队列示例。
基础使用
Stream 既然是一个数据类型,那么和其他数据类型相似,它也有一些自己的操作方法,例如:
| 描述 | 用法 |
|---|---|
| 添加消息到末尾,保证有序,可以自动生成唯一ID | XADD key ID field value [field value …] |
| 对流进行修剪,限制长度 | XTRIM key MAXLEN [~] count |
| 删除消息 | XDEL key ID [ID …] |
| 获取流包含的元素数量,即消息长度 | XLEN key |
| 获取消息列表,会自动过滤已经删除的消息 | XRANGE key start end [COUNT count] |
| 以阻塞或非阻塞方式获取消息列表 | XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key …] id [id …] |
| 创建消费者组 | XGROUP [CREATE key groupname id-or-] [DESTROY key groupname] [DELCONSUMER key groupname consumername] |
| 读取消费者组中的消息 | XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key …] ID [ID …] |
| 将消息标记为”已处理” | XACK key group ID [ID …] |
| 为消费者组设置新的最后递送消息ID | XGROUP SETID [CREATE key groupname id-or-] [DESTROY key groupname] |
| 删除消费者 | XGROUP DELCONSUMER [CREATE key groupname id-or-] [DESTROY key groupname] |
| 删除消费者组 | XGROUP DESTROY [CREATE key groupname id-or-] [DESTROY key groupname] [DEL |
| 显示待处理消息的相关信息 | XPENDING key group [start end count] [consumer] |
| 查看流和消费者组的相关信息 | XINFO [CONSUMERS key groupname] [GROUPS key] [STREAM key] [HELP] |
| 打印流信息 | XINFO STREAM [CONSUMERS key groupname] [GROUPS key] [STREAM key] [HELP] |
具体使用如下所述。
添加消息
1 | 127.0.0.1:6379> xadd key * name redis age 10 |
其中 * 表示使用 Redis 的规则:时间戳 + 序号的方式自动生成 ID,用户也可以自己指定 ID。
相关语法:
1 | xadd key ID field string [field string ...] |
查询消息的长度
1 | 127.0.0.1:6379> xlen key |
相关语法:
1 | xlen key |
删除消息
1 | 127.0.0.1:6379> xadd key * name redis |
相关语法:
1 | xdel key ID [ID ...] |
此命令支持删除一条或多条消息,根据消息 ID。
删除整个 Stream
1 | 127.0.0.1:6379> del key #删除整个 Stream |
相关语法:
1 | del key [key ...] |
此命令支持删除一个或多个 Stream。
查询区间消息
1 | 127.0.0.1:6379> xrange mq - + |
其中:- 表示第一条消息,+ 表示最后一条消息。
相关语法:
1 | xrange key start end [COUNT count] |
查询某个消息之后的消息
1 | 127.0.0.1:6379> xread count 1 streams mq 1580882060464-0 |
在名称为 mq 的 Stream 中,从消息 ID 为 1580882060464-0 的,往后查询一条消息。
相关语法:
1 | xread [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] ID [ID ...] |
此命令提供了阻塞读的参数 block,我们可以使用它读取从当前数据以后新增数据,命令如下:
1 | 127.0.0.1:6379> xread count 1 block 0 streams mq $ |
其中 block 0 表示一直阻塞,$ 表示从最后开始读取,这个时候新开一个命令行插入一条数据,此命令展示的结果如下:
1 | 127.0.0.1:6379> xadd mq * name sql age 20 #新窗口添加数据 |
代码实现
使用 Stream 消费分组实现消息队列的功能和列表方式的消息队列比较相似,使用 xadd 命令和 xread 循环读取就可以实现基础版的消息队列,具体代码如下:
1 | import com.google.gson.Gson; |
以上代码运行结果如下:
1 | 消息添加成功 ID:1580895735148-0 |
以上代码需要特殊说明的是,我们使用 new StreamEntryID().LAST_ENTRY 来实现读取当前时间以后新增的消息,如果要从头读取历史消息把这行代码中的 .LAST_ENTRY 去掉即可。
还有一点需要注意,在 Jedis 框架中如果使用 jedis.xread() 方法来阻塞读取消息队列,第二个参数 long block 必须设置大于 0,如果设置小于 0,此阻塞条件就无效了,我查看了 jedis 的源码发现,它只有判断在大于 0 的时候才会设置阻塞属性,源码如下:
1 | if (block > 0L) { |
所以 block 属性我们可以设置一个比较大的值来阻塞读取消息。
所谓的阻塞读取消息指的是当队列中没有数据时会进入休眠模式,等有数据之后才会唤醒继续执行。
消息分组
创建消费者组
xread 虽然可以扇形分发到 N 个客户端,然而,在某些问题中,我们想要做的不是向许多客户端提供相同的消息流,而是从同一流向许多客户端提供不同的消息子集。比如下图这样,三个消费者按轮训的方式去消费一个 Stream。
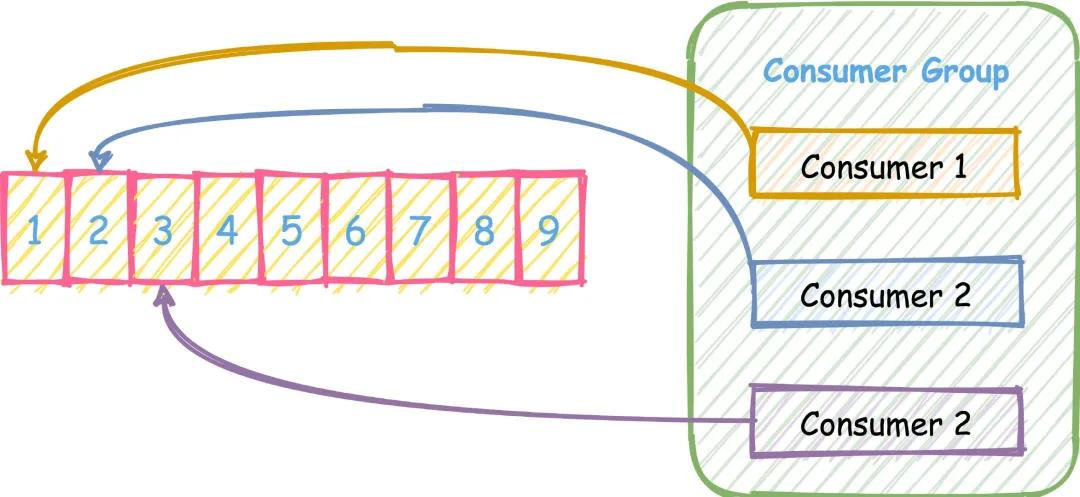
前面我们也提到过,Redis Stream 借鉴了很多 Kafka 的设计。
- Consumer Group:有了消费组的概念,每个消费组状态独立,互不影响,一个消费组可以有多个消费者
- last_delivered_id :每个消费组会有个游标 last_delivered_id 在数组之上往前移动,表示当前消费组已经消费到哪条消息了
- pending_ids :消费者的状态变量,作用是维护消费者的未确认的 id。pending_ids 记录了当前已经被客户端读取的消息,但是还没有 ack。如果客户端没有 ack,这个变量里面的消息 ID 会越来越多,一旦某个消息被 ack,它就开始减少。这个 pending_ids 变量在 Redis 官方被称之为 PEL,也就是 Pending Entries List,这是一个很核心的数据结构,它用来确保客户端至少消费了消息一次,而不会在网络传输的中途丢失了没处理。
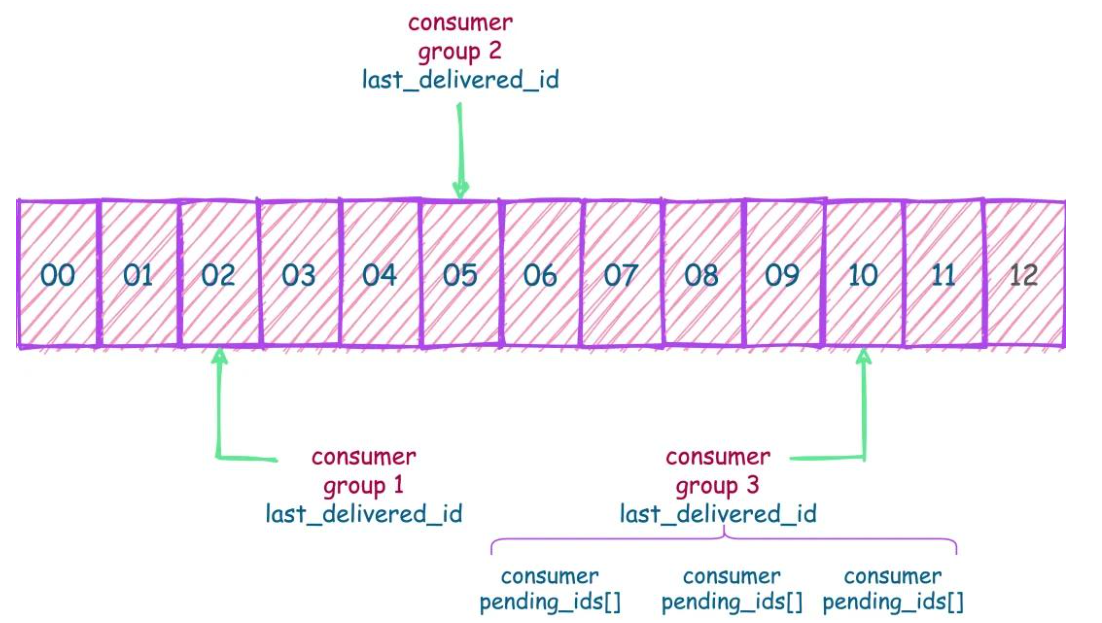
Stream 不像 Kafak 那样有分区的概念,如果想实现类似分区的功能,就要在客户端使用一定的策略将消息写到不同的 Stream。
- xgroup create:创建消费者组
- xgreadgroup:读取消费组中的消息
- xack:ack 掉指定消息
1 | 创建消费者组的时候必须指定 ID, ID 为 0 表示从头开始消费,为 $ 表示只消费新的消息,也可以自己指定 |
按消费组消费
Stream 提供了 xreadgroup 指令可以进行消费组的组内消费,需要提供消费组名称、消费者名称和起始消息 ID。它同 xread 一样,也可以阻塞等待新消息。读到新消息后,对应的消息 ID 就会进入消费者的 PEL(正在处理的消息) 结构里,客户端处理完毕后使用 xack 指令通知服务器,本条消息已经处理完毕,该消息 ID 就会从 PEL 中移除。
1 | # 消费组 mygroup1 中的 消费者 c1 从 mystream 中 消费组数据 |
代码实现
1 | import com.google.gson.Gson; |
以上代码运行结果如下:
1 | 消息添加成功 ID:1580971482344-0 |
到这里就已经对 Stream 实现消息队列有了基本的了解,由于笔者的 redis 版本较低,还不支持 Stream,所以对本小节的理解仅限于阅读层面,并未实际测试。
个人感觉,目前 Stream还是不能当作主流的 MQ 去使用,使用案例较少,所以仅限于学习一下就好了。
总结
本节不想其他 Redis 学习是的内容,最重要的东西在我的电脑里面不能运行,所以都是看别人文章来学习的,好在Redis做消息队列并不会经常使用,也不是主流,仅限了解就好。
在业务上要避免过度复用一个 Redis。既用它做缓存、做计算,还拿它做消息队列,这样的话 Redis 会很累的。
今天又是在学习 Java 路上的一天,在深入学习 Java 之后,我的眼界好像一下子就被打开了,之前一直觉得在用 Go 写代码时只需要用 go get …… 就可以得到想要的工具包,还嫌弃Java麻烦。有了 Maven 也可以实现类似的效果,加上 Java 的各种工具包十分充足,会有更好的开发体验。
Java是世界上最好的开发语言.go
参考
- https://www.51cto.com/article/640335.html
- https://learn.lianglianglee.com/%e4%b8%93%e6%a0%8f/Redis%20%e6%a0%b8%e5%bf%83%e5%8e%9f%e7%90%86%e4%b8%8e%e5%ae%9e%e6%88%98/24%20%e6%b6%88%e6%81%af%e9%98%9f%e5%88%97%e2%80%94%e2%80%94%e5%8f%91%e5%b8%83%e8%ae%a2%e9%98%85%e6%a8%a1%e5%bc%8f.md
- https://learn.lianglianglee.com/%e4%b8%93%e6%a0%8f/Redis%20%e6%a0%b8%e5%bf%83%e5%8e%9f%e7%90%86%e4%b8%8e%e5%ae%9e%e6%88%98/25%20%e6%b6%88%e6%81%af%e9%98%9f%e5%88%97%e7%9a%84%e5%85%b6%e4%bb%96%e5%ae%9e%e7%8e%b0%e6%96%b9%e5%bc%8f.md
- https://learn.lianglianglee.com/%e4%b8%93%e6%a0%8f/Redis%20%e6%a0%b8%e5%bf%83%e5%8e%9f%e7%90%86%e4%b8%8e%e5%ae%9e%e6%88%98/26%20%e6%b6%88%e6%81%af%e9%98%9f%e5%88%97%e7%bb%88%e6%9e%81%e8%a7%a3%e5%86%b3%e6%96%b9%e6%a1%88%e2%80%94%e2%80%94Stream%ef%bc%88%e4%b8%8a%ef%bc%89.md
- https://learn.lianglianglee.com/%e4%b8%93%e6%a0%8f/Redis%20%e6%a0%b8%e5%bf%83%e5%8e%9f%e7%90%86%e4%b8%8e%e5%ae%9e%e6%88%98/27%20%e6%b6%88%e6%81%af%e9%98%9f%e5%88%97%e7%bb%88%e6%9e%81%e8%a7%a3%e5%86%b3%e6%96%b9%e6%a1%88%e2%80%94%e2%80%94Stream%ef%bc%88%e4%b8%8b%ef%bc%89.md