
Golang中的闭包,你真的了解吗?
Go 语言从设计上对函数进行了优化和改进,让函数使用起来更加方便。
因为Go语言的函数本身可以作为值进行传递,既支持匿名函数和闭包,又能满足接口,所以 Go 语言的函数属于一等公民。
本文将由一道题引出 Go 中的闭包。这是 Go 语言爱好者周刊第 90 期的一道题目。以下代码输出什么?
1 | package main |
思考一下,这里会输出什么,如果再加上一行代码 fmt.Println(a("All")) ,它又会输出什么内容?
1 | //fmt.Println(b("All")) |
发现什么神奇的东西了吗,新加入的一行代码的输出结果竟然包含着第17行中输入的字符串,这和我们之前学过的东西都不太一样,别急,继续往下看吧。
什么是闭包?
维基百科对闭包的定义) :
在计算机科学中,闭包(英语:Closure),又称词法闭包(Lexical Closure)或函数闭包(function closures),是在支持头等函数的编程语言中实现词法绑定的一种技术。闭包在实现上是一个结构体,它存储了一个函数(通常是其入口地址)和一个关联的环境(相当于一个符号查找表)。环境里是若干对符号和值的对应关系,它既要包括约束变量(该函数内部绑定的符号),也要包括自由变量(在函数外部定义但在函数内被引用),有些函数也可能没有自由变量。闭包跟函数最大的不同在于,当捕捉闭包的时候,它的自由变量会在捕捉时被确定,这样即便脱离了捕捉时的上下文,它也能照常运行。捕捉时对于值的处理可以是值拷贝,也可以是名称引用,这通常由语言设计者决定,也可能由用户自行指定(如 C++)。
关于(函数)闭包,有几个关键点:
- 函数是一等公民;
- 闭包所处环境,可以引用环境里的值;
问到什么是闭包时,网上一般这么回答的:
在支持函数是一等公民的语言中,一个函数的返回值是另一个函数,被返回的函数可以访问父函数内的变量,当这个被返回的函数在外部执行时,就产生了闭包。
所以,上面题目中,函数 app 的返回值是另一个函数,因此产生了闭包。
回到最开始的问题:什么是闭包?
go官方的解释是:Go 函数可以是一个闭包。闭包是一个函数值,它引用了函数体之外的变量。 这个函数可以对这个引用的变量进行访问和赋值;换句话说这个函数被“绑定”在这个变量上。
简单来说,闭包是由函数和与其相关的引用环境组合而成的实体。

函数指的是在闭包实际实现的时候,往往通过调用一个外部函数返回其内部函数来实现的。用户得到一个闭包,也等同于得到了这个内部函数,每次执行这个闭包就等同于执行内部函数。
引用环境可以简单理解为在函数外部定义但在函数内被引用的变量。闭包跟函数最大的不同在于,当捕捉闭包的时候,它的所引用的外部变量会在捕捉时被确定,这样即便脱离了捕捉时的上下文,它也能照常运行。
闭包的本质
闭包是包含自由变量的代码块,这些变量不在这个代码块内或者任何全局上下文中定义,而是在定义代码块的环境中定义。由于自由变量包含在代码块中,所以只要闭包还被使用,那么这些自由变量以及它们引用的对象就不会被释放,要执行的代码为自由变量提供绑定的计算环境。
闭包的价值在于可以作为函数对象或者匿名函数,对于类型系统而言,这意味着不仅要表示数据还要表示代码。支持闭包的多数语言都将函数作为第一级对象,就是说这些函数可以存储到变量中作为参数传递给其他函数,最重要的是能够被函数动态创建和返回。
Golang 中的闭包同样也会引用到函数外的变量,闭包的实现确保只要闭包还被使用,那么被闭包引用的变量会一直存在。从形式上看,匿名函数都是闭包。
其实我们可以将闭包函数看成一个类 (C++),一个闭包函数调用就是实例化一个对象,闭包的自由变量就是类的成员变量,闭包函数的参数就是类的函数对象的参数。
这让我想起了一句名言:对象是附有行为的数据,而闭包是附有数据的行为。
闭包的意义
我们会发现,使用普通函数和全局变量完全可以实现和闭包相同的功能。
为什么不用全局变量?
- 缩小变量作用域,减少对全局变量的污染。上面的问题如果用全局变量进行实现,全局变量容易被其他人污染。
- 同时,如果我要实现n个闭包,如果我使用全局变量,就需要维护n个函数对应的全局变量。
使用闭包的一些例子
隔离数据
假设你想要创建一个函数,该函数可以访问即使在函数退出后仍会保留的数据。例如,您想要计算该函数被调用的次数,或者您想要创建一个斐波那契数生成器,但您不希望其他人访问该数据(这样他们就不会意外更改它)。您可以使用闭包来实现这一点。
1 | package main |
包装函数并创建中间件
Go 中的函数是一等公民。这意味着你不仅可以动态创建匿名函数,还可以将函数作为参数传递给函数。例如,在创建 Web 服务器时,通常会提供一个处理特定路由的 Web 请求的函数。
1 | package main |
在这种情况下,该函数hello()被传递给http.HandleFunc()函数,并在该路由匹配时被调用。
虽然此代码不需要闭包,但如果我们想用更多逻辑包装处理程序,闭包非常有用。一个完美的例子是当我们想要创建中间件来在处理程序执行之前或之后执行工作时。
让我们看看一个简单的计时器中间件在 Go 中是如何工作的。
1 | package main |
请注意,我们的timed()函数接受一个可用作处理程序函数的函数,并返回相同类型的函数,但返回的函数与传递给它的函数不同。返回的闭包记录当前时间,调用原始函数,最后记录结束时间并打印出请求的持续时间。所有这些都与处理程序函数内部实际发生的事情无关。
现在我们需要对处理程序进行计时,将它们包装起来timed(handler)并将闭包传递给http.HandleFunc()函数调用。
访问通常不可用的数据
闭包还可用于将数据包装在函数内部,否则函数通常无法访问这些数据。例如,如果你想在不使用全局变量的情况下为处理程序提供对数据库的访问权限,则可以编写如下代码。
1 | package main |
现在我们可以编写处理函数,就好像它们可以访问对象一样,Database同时仍返回具有预期签名的函数。这使我们能够绕过不允许我们传递自定义变量而不诉诸全局变量或任何此类变量的http.HandleFunc()事实。
使用闭包进行二分搜索
闭包也经常需要使用标准库中的包,比如sort包。
此包为我们提供了大量有用的函数和代码,用于对已排序列表进行排序和搜索。例如,如果您想对整数切片进行排序,然后在切片中搜索数字 7,则可以sort像这样使用该包。
1 | package main |
但是,如果你想要搜索每个元素都是自定义类型的切片,会发生什么情况?或者,如果你想要查找第一个大于或等于 7 的数字的索引,而不仅仅是第一个 7 的索引,会发生什么情况?
为此,您应该使用sort.Search()函数,并且需要传入一个闭包,该闭包可用于确定特定索引处的数字是否符合您的条件。
sort.Search是二分查找该
sort.Search函数执行二分搜索,因此它期望一个闭包,该闭包将对满足条件之前的任何索引返回 false,对满足条件之后的任何索引返回 true。这意味着您不能使用它来“在列表中找到 7 的索引”,而是需要将您的逻辑改写为“第一个大于或等于 7 的数字的索引是什么?”,然后在获取索引后检查该数字是否为 7。
让我们使用上面描述的例子来实际看一下这一点;我们将搜索列表中大于或等于 7 的第一个数字的索引。
1 | package main |
在这个例子中,我们的闭包是作为第二个参数传递的简单小函数sort.Search()。
1 | func(i int) bool { |
numbers即使从未传入切片,此闭包也会访问切片,并对任何大于或等于 7 的数字返回 true。通过这样做,它sort.Search()允许在无需了解您正在使用的底层数据类型或您试图满足的条件的情况下工作。它只需要知道特定索引处的值是否符合您的条件。
用闭包 + defer 进行处理异常
1 | package main |
结果输出:
1 | some except had happend: runtime error: invalid memory address or nil pointer dereference |
recover 函数用于终止错误处理流程。一般情况下,recover 应该在一个使用 defer 关键字的函数中执行以有效截取错误处理流程。如果没有在发生异常的 goroutine 中明确调用恢复过程(调用 recover 函数),会导致该 goroutine 所属的进程打印异常信息后直接退出
对于第三方库的调用,在不清楚是否有 panic 的情况下,最好在适配层统一加上 recover 过程,否则会导致当前进程的异常退出,而这并不是我们所期望的。
坑
这么有趣的东西,肯定有着不少的坑,也是我们在实际开发时要注意的东西。
for range 中使用闭包
1 | func main() { |
来看看结果:
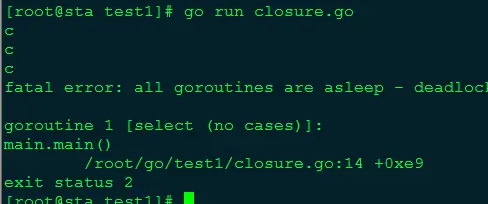
输出的结果不期而然,大家的结果也不一定和我相同。
对比下面的改进:
1 | func main() { |
所以结果当然是:
1 | "a" |
由于使用了 go 协程,并非顺序输出。
解释:也不用多解释了吧,在没有将变量
v的拷贝值传进匿名函数之前,只能获取最后一次循环的值,这是新手最容易遇到的坑。
循环闭包引用
1 | package main |
会输出什么?
每次 append 操作仅将匿名函数放入到列表中,但并未执行,并且引用的变量都是 i,随着 i 的改变匿名函数中的 i 也在改变,所以当执行这些函数时,他们读取的都是环境变量 i 最后一次的值。
解决方法
声明新的变量
1 | package main |
- 声明新变量:j := i,且把之后对 i 的操作改为对 j 操作。
- 声明新同名变量:i := i。注意:这里短声明右边是外层作用域的 i,左边是新声明的作用域在这一层的 i。原理同上。
这相当于为这三个函数各声明一个变量,一共三个,这三个变量初始值分别对应循环中的 i 并且之后不会再改变。
声明新匿名函数并传参
1 | package main |
现在 println(i)使用的 i是通过函数参数传递进来的,并且 Go 语言的函数参数是按值传递的。
现在相当于在这个新的匿名函数内声明了三个变量,被三个闭包函数独立引用。原理跟第一种方法是一样的。
闭包的实现
定义后立即被调用
因为只会被使用一次,所以应该力图避免闭包对象的内存分配操作,那怎么优化一下呢?一下面的示例代码为例:
1 | func(a int) { |
在文章开头我们提到过闭包跟函数最大的不同在于,当捕捉闭包的时候,它的所引用的外部变量会在捕捉时被确定,这样即便脱离了捕捉时的上下文,它也能照常运行。如果闭包在定义后立即被调用,那它不会存在脱离上下文的使用场景,这时候其实可以将它转为简单函数的调用形式。
上面的闭包将被转换为简单函数调用的形式:
1 | func(byval int, &byref *int, a int) { |
我们注意到byval是值捕获,byref是引用捕获,这其实是根据变量在函数内部会不会被修改来决定的。我们知道在闭包内部修改变量会影响到外部环境,如果变量在闭包中会被修改,使用值捕获显然是不太合适的。
定义后没有立即调用
这种情况下同一个闭包可能调用多次,这就需要创建闭包对象了,如何实现呢?
- 如果变量是在函数内部不会被修改,并且该变量占用存储空间小于
2*sizeof(int),那么就通过在函数体内创建局部变量的形式来捕获的变量,相比于直接捕获变量地址,这么做的好处应该是考虑到减少引用数量、减少逃逸分析相关的计算。 - 如果变量在函数内部会被修改,或者变量占用存储空间较大(拷贝到本地做局部变量代价太大),则在捕获变量的地址。

相关源码
1 | func transformclosure(xfunc *Node) { |
变量捕获
那么具体是怎么捕获的呢?
在Go 语言中函数也是一种变量,和普通变量一样可以通过参数传递,可以做函数返回值。Go 语言把这样的函数变量称为 function value,它本质上是一个指针,指向一个 runtime.funcval 结构体,这个结构体保存了函数的入口地址。
1 | type funcval struct { |
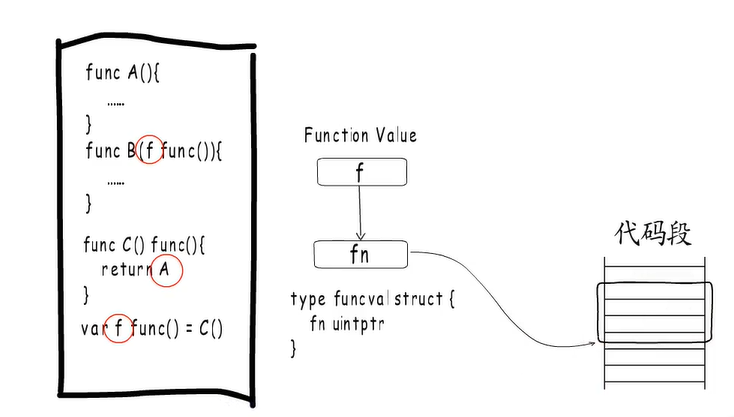
举个例子:func A 的指令位于代码段的 addr1。由于 func A 对应的 function value 没有捕获列表,编译期间编译器会在只读数据段分配一个 function value 结构体,这个结构体本身的地址是 addr2 ,它保存了 func A 的地址 addr1,多次 func A 调用共享一个 funcval。执行阶段,addr2 会被赋予 f1 与 f2。执行 f1 就是通过 f1 找出对应的 funcval,进而拿到 func A 入口地址。
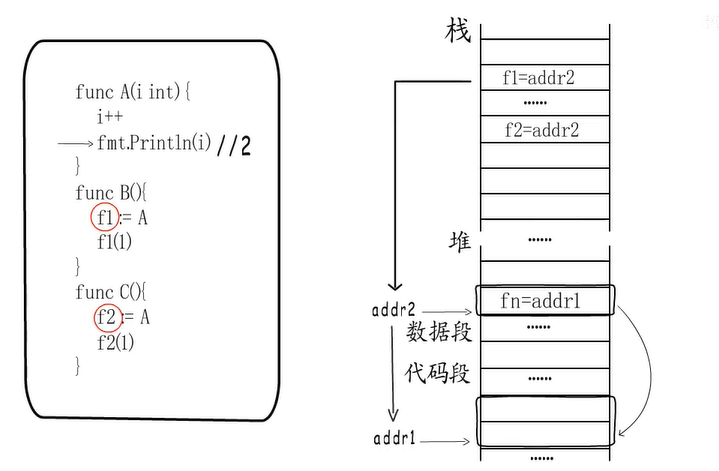
为什么不直接通过addr1调用函数,而要添加一层中间层function value呢?
这其实是为了支持闭包的实现,function value这一中间层方便我们将同一个函数绑定到不同的引用环境上。
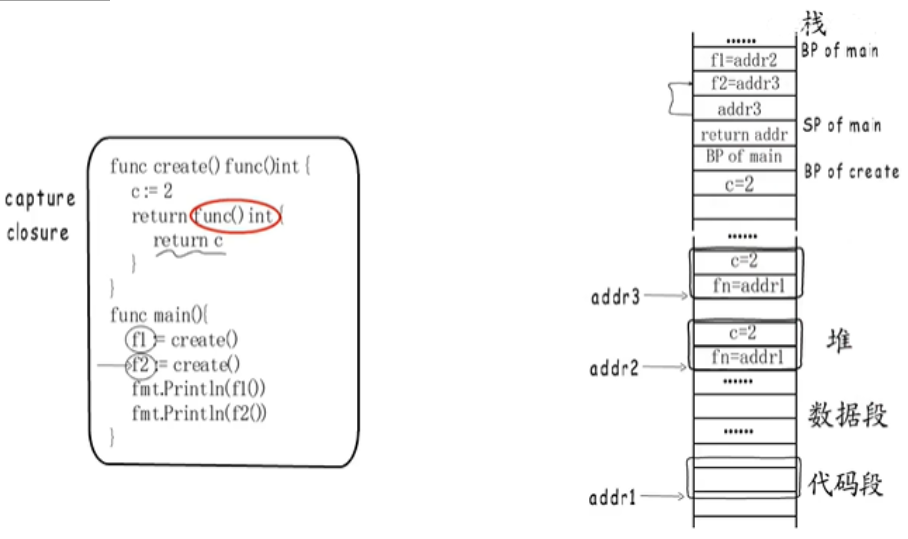
通常来讲,局部变量都是分配在栈的,上图也是这样。但是,如果捕获变量的值会发生改变,Go 编译器会在堆上分配局部变量,栈上只保存一个地址。这就是所谓的“局部变量堆分配”。function value 的捕获列表保存局部变量的地址,这样闭包函数和外层函数就指向同一个变量了。
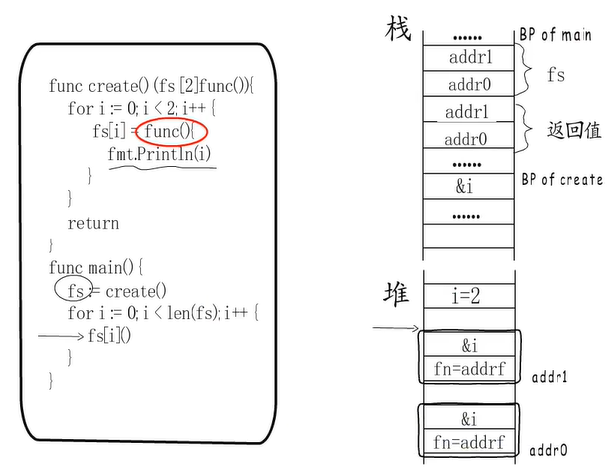
来看一个例子:
1 | package main |
上述代码会输出什么?
我们会发现它们输出的地址是一样的,不可思议。按道理每次分配新的funcval,地址是不可能相等的。其实fmt.Printf识别出f1和f2是函数变量后,把funcval.fn给打印出来了,打印的是函数的真实地址,而不是funcval的地址。
如果要查看真实地址,可以采用下面这种写法:
1 | package main |
总结
闭包实际上就是一种语法糖机制,这种语法糖机制可以简化编程,比如,有时候对外部的变量进行访问,没这种语法糖机制将会编写冗余的代码。而这正也是可以把这种闭包机制归结为一种设计模式。但是由于使用闭包会导致代码不够清晰,使用不当还会导致得到错误的结果。所以一般不建议使用闭包。
不知道为什么,在我的环境下运行坑这一部分的代码时,是不会出现任何问题的,可能是 go 的新版本把这些问题给改了吧,也可能是编译器的优化问题。
参考
https://llmxby.com/2022/08/27/%E6%8E%A2%E7%A9%B6Golang%E4%B8%AD%E7%9A%84%E9%97%AD%E5%8C%85/
https://learnku.com/articles/59988
https://www.calhoun.io/5-useful-ways-to-use-closures-in-go/
https://polarisxu.studygolang.com/posts/go/action/go-closure/