
顺序存储两兄弟——数组和切片,到底有什么区别?
数组是一个长度固定的数据类型,其长度在定义时就已经确定,不能动态改变;切片是一个长度可变的数据类型,其长度在定义时可以为空,也可以指定一个初始长度。
在 Go 语言中,数组和切片看起来很像,但其实它们又有很多的不同之处,这篇文章就来说说他们到底有哪些不同。
另外,这个问题在面试中也经常会被问到,属于入门级题目,看完文章之后,相信你会有一个很好的答案。
数组
数组——一个几乎所有主流语言都支持的数据结构,它是一篇连续的内存区域。Go 语言中的数组和其他语言中的数组有显著不同的特性,例如,其不能进行扩容、在复制和传递时为值复制。开发者通常将数组与 Go 语言中另一个重要的结构——切片进行对比,这个会在后面的部分介绍和对比。
概述
数组是由相同类型的集合组成的数据结构,计算机会为数组分配一块连续的内存来保存其中的元素,我们可以利用数组中元素的索引快速访问特定元素,常见的数组大多都是一味的线性数组,而多维数组在数值和图形计算领域有着比较常见的应用。
数组作为一种基本的数据结构,我们通常会从两个维度描述一个数组,也就是数组中存储的元素类型和数组最大能存储元素的个数。
Go 语言数组在初始化之后大小就无法改变,存储元素类型相同但是大小不同的数组类型在 Go 语言看起来也是完全不同的,只有两个条件都相同才是同一类型。
1 | func NewArray(elem *Type, bound int64) *Type { |
编译期间的数组类型是由上述的 cmd/compile/internal.types.NewArray 函数生成的,该类型包含两个字段,分别是元素类型 Elem 和数组大小 Bound ,这两个字段共同构成了数组类型,而当前数组是否应该在堆栈中初始化也在编译期间就确定了。
1 | type Array struct { |
初始化
1 | var nums [3]int // 声明并初始化为默认零值 |
前两种声明方式严格意义上来说其实是同一种类型,区别在于是否进行初始化。第三种声明方式是 Go 语言中对于数组的一种语法糖,可以不指定长度,编译器会自动推断,在编译期间就会被转换成前一种。
下面我们来看一下编译器的推导过程。
上限推导
两种不同的声明方式导致编译器做出完全不同的处理,如果使用的是第一种方式,那么变量的类型在编译进行到类型检查阶段就会被提取出来,随后使用 cmd/compile/internal/types.NewArray 创建包含数组大小的 cmd/compile/internal/types.Array 结构体。
当使用第二种声明方式时,编译器会在 cmd/compile/internal/gc.typecheckcomplit 函数中对该数组的大小进行推导:
1 | func typecheckcomplit(n *Node) (res *Node) { |
这个删减后的 cmd/compile/internal/gc.typecheckcomplit 会调用 cmd/compile/internal/gc.typecheckarraylit 通过遍历元素的方式来计算数组中元素的数量。
所以我们可以看出 [...]T{1, 2, 3} 和 [3]T{1, 2, 3} 在运行时是完全等价的,[...]T 这种初始化方式也只是 Go 语言为我们提供的一种语法糖,当我们不想计算数组中的元素个数时可以通过这种方法减少一些工作量。
语句转换
对于一个由字面量组成的数组,根据数组元素数量的不同,编译器会在负责初始化字面量的 cmd/compile/internal/gc.anylit 函数中做两种不同的优化:
- 当元素数量小于或者等于 4 个时,会直接将数组中的元素放置在栈上;
- 当元素数量大于 4 个时,会将数组中的元素放置到静态区并在运行时取出;
1 | func anylit(n *Node, var_ *Node, init *Nodes) { |
当数组的元素小于或者等于四个时,cmd/compile/internal/gc.fixedlit 会负责在函数编译之前将 [3]{1, 2, 3} 转换成更加原始的语句:
1 | func fixedlit(ctxt initContext, kind initKind, n *Node, var_ *Node, init *Nodes) { |
当数组中元素的个数小于或者等于四个并且 cmd/compile/internal/gc.fixedlit 函数接收的 kind 是 initKindLocalCode 时,上述代码会将原有的初始化语句 [3]int{1, 2, 3} 拆分成一个声明变量的表达式和几个赋值表达式,这些表达式会完成对数组的初始化:
1 | var arr [3]int |
但是如果当前数组的元素大于四个,cmd/compile/internal/gc.anylit 会先获取一个唯一的 staticname,然后调用 cmd/compile/internal/gc.fixedlit 函数在静态存储区初始化数组中的元素并将临时变量赋值给数组:
1 | func anylit(n *Node, var_ *Node, init *Nodes) { |
假设代码需要初始化 [5]int{1, 2, 3, 4, 5},那么我们可以将上述过程理解成以下的伪代码:
1 | var arr [5]int |
总结起来,在不考虑逃逸分析的情况下,如果数组中元素的个数小于或者等于 4 个,那么所有的变量会直接在栈上初始化,如果数组元素大于 4 个,变量就会在静态存储区初始化然后拷贝到栈上,这些转换后的代码才会继续进入中间代码生成和机器码生成两个阶段,最后生成可以执行的二进制文件。
访问和赋值
无论是在栈上还是静态存储区,数组在内存中都是一连串的内存空间,我们通过指向数组开头的指针、元素的数量以及元素类型占的空间大小表示数组。如果我们不知道数组中元素的数量,访问时可能发生越界;而如果不知道数组中元素类型的大小,就没有办法知道应该一次取出多少字节的数据,无论丢失了哪个信息,我们都无法知道这片连续的内存空间到底存储了什么数据。
数组访问越界时非常严重的错误,Go 语言中可以在编译期间的静态类型检查判断数组越界,cmd/compile/internal/gc.typecheck1 会验证访问数组的索引:
1 | func typecheck1(n *Node, top int) (res *Node) { |
- 访问数组的索引是非整数时,报错 “non-integer array index %v”;
- 访问数组的索引是负数时,报错 “invalid array index %v (index must be non-negative)”;
- 访问数组的索引越界时,报错 “invalid array index %v (out of bounds for %d-element array)”;
数组和字符串的一些简单越界错误都会在编译期间发现,例如:直接使用整数或者常量访问数组;但是如果使用变量去访问数组或者字符串时,编译器就无法提前发现错误。
Go 语言对于数组的访问还是有着比较多的检查的,它不仅会在编译期间提前发现一些简单的越界错误并插入用于检测数组上限的函数调用,还会在运行期间通过插入的函数保证不会发生越界。
参数传递
如果数组作为函数的参数,那么实际传递的是一份数组的拷贝,而不是数组的指针。这也就意味着,在函数中修改数组的元素是不会影响到原始数组的。
切片
Go语言中的切片(Slice)在某种程度上和其他语言(例如C语言)中的数组在使用中有许多相似的地方。但是 Go语言中的切片有许多独特之处,例如,切片是长度可变的序列。序列中的每个元素都有相同的类型。一个切片一般写作 []T,其中T代表 Slice 中元素的类型。和数组不同的是,切片不用指定固定长度。
由于数组 Array 的特性,在 Go 代码中适用场景有限,而切片 Slice 会用得非常多。切片 Slice 基于数组,但提供了更高的灵活性,它可以动态地扩容。切片的类型和长度无关。
概述
Slice 的底层数据是数组,Slice 是对数组的封装,它描述一个数组的片段。两者都可以通过下标来访问单个元素。
数组是定长的,长度定义好之后,不能再更改。在 Go 中,数组是不常见的,因为其长度是类型的一部分,限制了它的表达能力,比如 [3]int 和 [4]int 就是不同的类型。
数组就是一片连续的内存, Slice 实际上是一个结构体,包含三个字段:长度、容量、底层数组。
1 | // runtime/slice.go |
内置的 len和 cap函数可以分别获取切片的长度和容量。
slice 的数据结构如下:
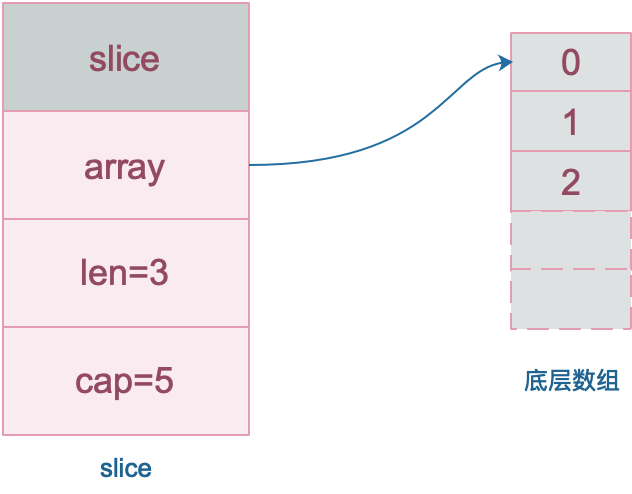
注意,底层数组是可以被多个 Slice 同时指向的,因此对一个 Slice 的元素进行操作是有可能影响到其他 Slice 的。
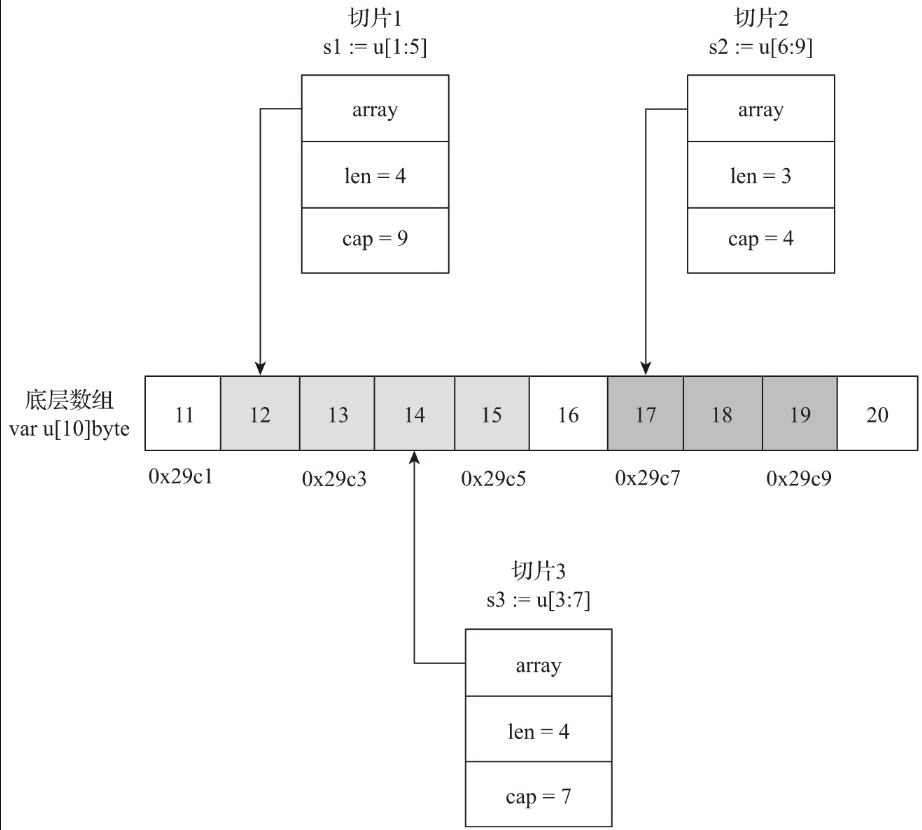
初始化
1 | var slice1 []int |
切片有长度和容量的区别,可以在初始化时指定。由于切片具有可扩展性,所以当它的容量比长度大时,意味着为切片元素的增长预留了内存空间。